

这是博客文章系列的第 3 部分,最初发表在我的个人博客上。 从第 1 部分 和第 2 部分 开始您的旅程。
我们可以将向量存储在 Arroy 中并有效地计算搜索树节点,但我们仍然需要一些功能才能使其在 Meilisearch 中可用。我们的全文搜索引擎对过滤有很好的支持;选择文档子集是支持的重要功能。例如,我们最大的客户之一需要能够通过超过 1 亿个 YouTube 视频元数据及其关联的图像嵌入进行过滤,以有效地选择在特定时间段内发布的视频,例如一天或一周。这代表了我们旨在通过我们的过滤系统解决的可扩展性和响应性挑战,使其成为定制我们开发的完美用例。
Meilisearch 支持以下操作符对文档的可过滤属性进行操作:<、<=、=、!= >= 和 >。在内部,我们广泛地使用RoaringBitmap,它们是经过良好优化的整数集,支持快速二进制操作,例如并集和交集。当引擎收到包含过滤器的用户请求时,它首先从过滤器中计算将输入到搜索算法中的文档子集,该算法按质量对文档进行排序。此子集由一个RoaringBitmap 表示。
在 Arroy 之前它是如何工作的?
仅对过滤后的文档子集进行排序自 2018 年以来一直运行良好,但现在我们有了新的数据结构要搜索,我们需要看看如何实现它。引擎已经支持向量存储功能几个月了,但效率低下。我们正在使用内存中的 HNSW 并将整个数据结构反序列化到内存中,搜索目标向量的最近邻,它正在返回一个迭代器。
fn vector_store(db: Database, subset: &RoaringBitmap, target_vec: &[f32]) -> Vec<DocumentID> {
// This takes a lot of time and memory.
let hnsw = db.deserialize_hnsw();
let mut output = Vec::new();
for (vec_id, vec, dist) in hnsw.nearest_neighbors(target_vec) {
let doc_id = db.document_associated_to_vec(vec_id).unwrap();
if !output.contains(&doc_id) {
output.push(doc_id);
if output.len() == 20 { break }
}
}
output
}您可能想知道为什么我们要检索与向量 ID 关联的文档 ID。Meilisearch 从向量存储功能开始就支持每个文档的多个向量。这很不幸,因为我们必须查找正在迭代的每个向量。我们需要维护这个查找表。如果子集足够小,迭代器可以迭代整个向量数据集,例如 document.user_id = 32。我们希望文档操作是原子且一致的,因此我们必须将 HNSW 存储在磁盘上,并避免在 LMDB 事务和此向量存储数据结构之间维护同步。哦!并且库不支持增量插入。每次插入单个向量时,我们都必须从头开始重建内存中的 HNSW。
将 Arroy 集成到 Meilisearch
当我们更新 Meilisearch 以包含新的向量存储 arroy 时,我们第一次尝试了多人编程。在这种情况下,我们所有人同时编写代码。听起来可能会减慢我们的速度,但实际上它使我们超级高效!通过在问题出现时一起解决问题,我们比单独工作更快地将 arroy 融入 Meilisearch。
Arroy 不同之处在于它不会返回迭代器以返回搜索结果。现在,我们的搜索引擎更智能,可以计算出需要返回的准确结果数量,即使要考虑过滤器。这种团队合作改善了我们的搜索工具,并向我们表明,在面对重大技术挑战时,团队合作是关键。
在 Arroy 中搜索时过滤
您可以在 本系列的第 1 部分 中找到有关 arroy 内部数据结构的描述。以下列出了您可以找到的不同类型的节点
- 项目节点。用户提供的原始向量。左边的几个点。
- 普通节点,也称为分割平面。它们表示将项目节点子集一分为二的超平面。
- 后代节点。它们是树叶,由您在遵循某个普通节点路径时会找到的项目 ID 组成。
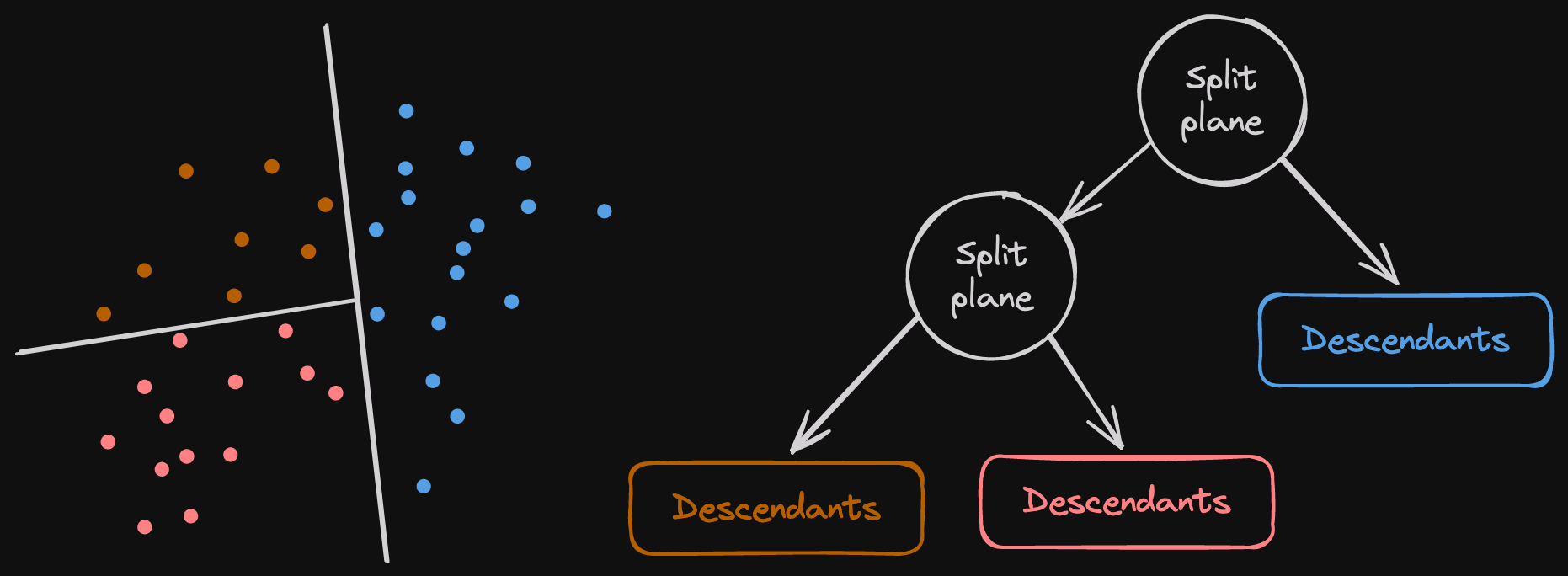
典型的搜索将加载与无限距离关联的二叉堆中的所有普通节点。请记住,存在许多随机生成的树,因此存在许多入口点。升序距离对二叉堆进行排序;找到的最短节点将首先弹出。
在搜索算法中,我们从这个堆中弹出最近的项目。如果它是普通节点,我们将获取超平面的左侧和右侧
- 如果我们再次找到普通节点,我们将与目标/查询向量的正负距离相关联超平面的距离。
- 如果我们找到后代节点,我们不会将它们推入队列,而是直接将它们添加到潜在输出列表中,因为它们表示我们找到的最近向量。
您可能已经注意到我要去哪里,但这就是魔术发生的地方。我们修改了 arroy 以将后代列表存储在 RoaringBitmap 中,而不是原始整数列表中。与原始 Spotify 库相比,这也是另一个改进,因为这些列表的权重更轻。现在,与过滤后的子集进行交集变得更加容易。
但是,始终存在一个问题:向量 ID 不是文档 ID,Meilisearch 在执行过滤器后只知道文档。遍历我之前提到的查找表,使用与过滤后的文档相对应的所有向量 ID 构建最终位图在许多文档属于此子集时将效率低下,例如 document.user_id != 32。我不建议在搜索函数中使用 O(n) 算法。
使用多个索引进行高效过滤
幸运的是,我们在 arroy 中开发了一个有趣的、本来不打算这样使用功能:支持在单个 LMDB 数据库中使用多个索引。我们最初开发了多个索引功能,以便只能打开单个 LMDB 数据库来存储不同的向量类型。是的!在 Meilisearch v1.6 中,您可以描述存在于单个索引中的不同嵌入器。您可以使用不同的维数和距离函数来识别不同的向量,这些向量可以存储在单个文档中。还可以在单个文档中为与相同嵌入器关联的单个文档定义多个向量。
索引由一个 u16 标识。此功能可以欺骗算法,使其比之前的 HNSW 解决方案更有效。在文档中使用一个存储器作为嵌入器和向量很有趣,因为我们现在可以使用文档 ID 来识别向量。不再需要查找数据库和向量 ID。向量 ID 被简化为文档 ID。我们可以使用过滤器的输出来过滤 arroy 索引。
Meilisearch 侧面的搜索算法有所不同。我们请求每个 arroy 索引中的最近邻,按文档 ID 对结果进行排序,以便能够对它们进行去重,并且不会多次返回相同的文档,然后按距离再次对它们进行排序,然后仅返回前 20 个文档。这似乎很复杂,但我们谈论的是每个文档的向量数量为 20 个文档。通常,用户将只有一个向量。
fn vector_search(
rtxn: &RoTxn,
database: Database,
embedder_index: u8,
limit: usize,
candidates: &RoaringBitmap,
target_vector: &[f32],
) -> Vec<(DocumentId, f32)> {
// The index represents the embedder index shifted and
// is later combined with the arroy index. There is an arroy
// index by vector for a single embedded in a document.
let index = (embedder_index as u16) << 8;
let readers: Vec<_> = (0..=u8::MAX)
.map(|k| index | (k as u16))
.map_while(|index| arroy::Reader::open(rtxn, index, database).unwrap())
.collect();
let mut results = Vec::new();
for reader in &readers {
let nns = reader.nns_by_vector(rtxn, target_vector, limit, None, Some(candidates)).unwrap();
results.extend(nns_by_vector);
}
// Documents can have multiple vectors. We store the different vectors
// into different arroy indexes, we must make sure we don't find the nearest neighbors
// vectors that correspond to the same document.
results.sort_unstable_by_key(|(doc_id, _)| doc_id);
results.dedup_by_key(|(doc_id, _)| doc_id);
// Sort back the documents by distance
results.sort_unstable_by_key(|(_, distance)| distance);
results
}这些改进背后的设计理念
我们正在努力使 Meilisearch 足够灵活,以满足每个人的需求。无论您的文档是由单个嵌入支持的,例如 OpenAI 的巧妙工具生成的嵌入,还是与文本和图像嵌入混合使用,正如许多电子商务网站所做的那样,我们希望您的搜索体验是无缝的。对于使用来自多模式嵌入器的多个嵌入的超级用户,我们并没有忘记您。我们最新的改进确保每个人都可以增量地更新和微调其搜索索引,使整个过程像黄油一样顺滑。
衷心感谢大家:总结一下,向小组致敬 - @dureuill、@irevoire 和 @ManyTheFish - 由于他们的天才和艰苦工作,使我们的想法变为现实。请注意 @irevoire 即将发表的文章,他将在文章中解释我们如何在 Arroy 中实现增量索引 - 意味着您可以添加新向量而无需从头开始重建所有内容。很快就会有更多这方面的信息!
您可以在 Lobste.rs、Hacker News、Rust 子版块 或 X(前身为 Twitter) 上评论这篇文章。
Meilisearch 是一个开源搜索引擎,它不仅为最终用户提供最先进的体验,而且还提供简单直观的开发人员体验。
有关 Meilisearch 的更多信息,您可以加入 Discord 上的社区,或订阅 新闻稿。您可以通过查看 路线图 并参与 产品讨论 来详细了解该产品。