

程序可以向操作系统请求多少虚拟内存?当然,不会超过机器上安装的 RAM 数量?也许我们可以加上交换或页面文件的配置数量?等等 - 这也取决于其他进程使用多少内存吗?
我们在 Meilisearch 中以艰难的方式找到了这些问题的准确答案。在本文中,我们将分享我们关于虚拟内存及其与应用程序交互的令人惊讶的微妙方式的学习成果。
Meilisearch 是一个开源搜索引擎,旨在提供闪电般快速的、高度相关的搜索,并且集成工作量很少。它允许将磁盘上的文档存储在称为索引的组中,并搜索这些索引以获取与每个查询相关的文档。
自Meilisearch v1.1(我们现在处于v1.6!)以来,我们取消了对索引数量和最大大小的限制。在本文中,我们将分享动态虚拟内存管理如何成为实现这些改进的关键。

虚拟内存及其对 Meilisearch 的限制
什么是虚拟内存?
虚拟内存是操作系统 (OS) 创建的抽象,用于管理物理内存。这种抽象允许操作系统为正在运行的进程提供虚拟地址空间。每个进程的虚拟地址空间与其他进程隔离。这样,进程就会被阻止意外地(或恶意地)访问属于其他进程的内存。这与所有进程直接访问物理内存形成对比,这种情况在历史上较旧的操作系统中存在,并且在某些嵌入式系统中仍然存在。
操作系统通过将应用程序程序操作的虚拟内存页面转换为物理内存中的对应页面来实现虚拟内存。
虚拟内存还使操作系统能够实现一种称为交换(也称为页面文件)的机制。通过将虚拟内存页面映射到较慢的磁盘存储内存,以便在下次访问该页面时将其重新加载到物理内存中,虚拟内存还提供了一种解决可用物理内存量的方法。
下图显示了两个进程的虚拟内存示例,其中每个进程只能访问操作系统为其分配的物理内存部分。进程 A 的一个页面被“交换出”到磁盘上,并在下次访问时从磁盘加载到物理内存中。

Meilisearch 中的虚拟内存
在 Unix 环境中,您可以使用诸如htop之类的命令行界面工具查看进程使用了多少虚拟内存。以下是 Meilisearch 实例的命令输出
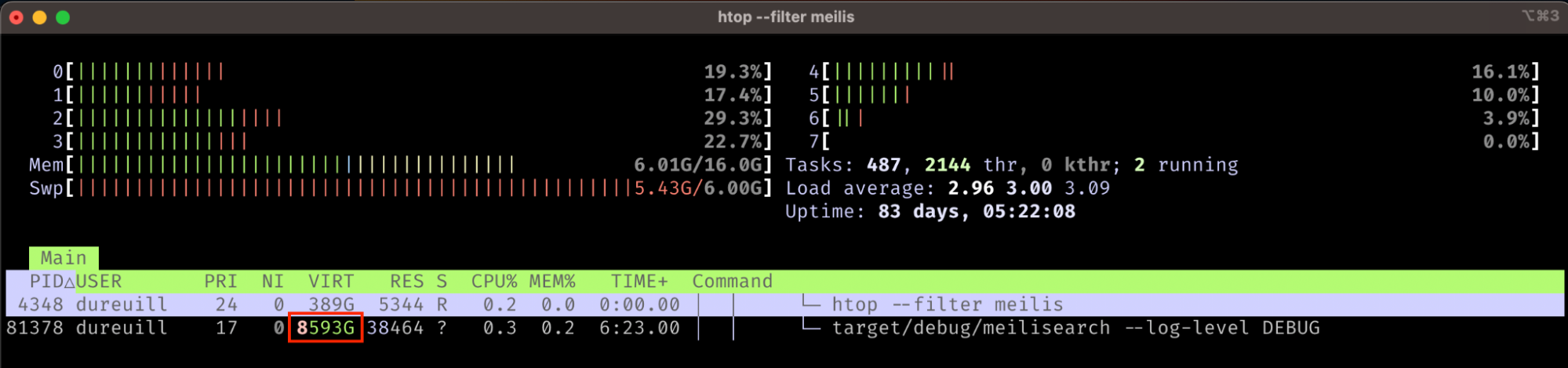
如您所见,Meilisearch 使用了高达 8593 GB 的虚拟内存 - 远远超过了这台机器上可用的物理内存 (16 GB) 和磁盘 (1000 GB)。虚拟内存可以为进程提供实际上无限的内存。请注意,物理内存使用量 - 实际 RAM - 远低于此,仅使用了 38464 KB。
负责 Meilisearch 虚拟内存使用量的主要因素是内存映射,其中操作系统将文件的原始内容映射到虚拟内存。Meilisearch 使用LMDB 键值存储将存储在磁盘上的索引的内容映射到虚拟内存。这样,对索引文件的任何读写操作都通过虚拟内存缓冲区进行。操作系统透明地、有效地将内存页面在物理内存和磁盘之间进行交换。
现在,问题在于这样的内存映射文件可能会占用虚拟地址空间的相当一部分。当映射一个 10 GB 的文件时,您实际上需要一个相应的 10 GB 连续虚拟内存缓冲区。
此外,通过内存映射写入文件可以的最大大小必须在创建映射时指定,以便操作系统可以确定要用于映射的连续虚拟内存缓冲区的大小。
回到 Meilisearch 使用的 8593 GB 虚拟内存,我们现在明白,其中大部分实际上用于创建文档索引的内存映射。Meilisearch 分配了这么多内存以确保这些内存映射足够大以容纳磁盘上索引的增长。
但是极限是多少?进程的虚拟内存可以增长多少?因此,可以同时存在多少个索引,以及它们的最大大小是多少?
128 TB 只能容纳这么多索引!
从理论上讲,在 64 位计算机上,虚拟地址空间为 2^64 字节。这是 18.45 艾字节。超过 1600 万太字节!然而,在实践中,操作系统为进程分配的虚拟地址空间要小得多:Linux 上为 128 TB,Windows 上为 8 TB。
128 TB 听起来可能很多。但是,需要考虑在 Meilisearch 实例可以使用的索引数量 (N) 和索引的最大大小 (M) 之间权衡。基本上,我们需要 N * M 保持在 128 TB 的限制以下。由于文档索引有时会增长到数百 GB,因此这是一个挑战。
在 Meilisearch v1.0 之前的版本中,这种权衡通过 --max-index-size CLI 参数暴露出来。这允许开发人员使用 100 GB 的默认值定义每个索引的映射大小。使用这些以前的版本,如果您想拥有大于 100 GB 的索引,则需要将 --max-index-size 参数的值更改为索引所需的估计最大大小。
因此,虽然这并不十分明显,但更改 --max-index-size 参数的值会限制 Meilisearch 实例可以使用的索引数量:在 Linux 上,默认值为 100 GB 时约为 1000 个索引,在 Windows 上约为 80 个索引。增加参数以适应更大的索引将减少最大索引数量。例如,1 TB 的最大索引大小会将您限制在 100 个索引内。
那么如何决定 --max-index-size 的值?没有直接的答案。因为 Meilisearch 构建称为倒排索引的数据结构,其大小取决于以非平凡方式被索引的文本的特征。因此,索引的大小难以事先估计。
将这个有微妙影响的决定留给用户感觉违背了我们拥有一个简单、易用的、具有良好默认值的引擎的目标。随着v1.0 的即将发布,我们不想稳定 --max-index-size 参数。因此,我们决定在 v1.0 中删除此选项。我们暂时将索引的内存映射大小硬编码为 500 GB,并计划在 v1.1 版本中提供更直观的解决方案。
进入动态虚拟地址空间管理。
使用动态虚拟地址空间管理,我们将无限前进
与动态数组的类比
让我们将当前的问题与固定大小的数组进行比较。在编译语言中,固定大小的数组要求开发人员在编译时定义其大小,因为其大小在运行时无法更改。使用已弃用的 --max-index-size 参数,Meilisearch 用户面临着类似的约束。他们必须确定最佳索引大小,从而在大小和索引总数之间进行权衡。
真正使这个问题无法解决的是索引的两个相互竞争的用例
- 将大量大型文档存储在索引中,从而使索引的大小达到数百 GB;
- 存储许多索引,可能是数千个(尽管这通常是为了解决多租户问题,而多租户问题应该使用租户令牌来实现)。
用户基本上面临着困境:拥有大型索引,但限制索引数量,或者限制索引大小以允许更多索引。我们必须想出更好的方法。
在编译语言中,开发人员在事先不知道数组大小时使用动态数组。动态数组是一个数据结构,它由三部分信息组成
- 指向动态分配的连续数组的指针;
- 分配给此数组的大小,表示为容量;以及
- 存储在数组中的当前元素数量。
向动态数组添加元素需要检查数组的剩余容量。如果新元素太大而无法容纳在现有数组中,则会以更大的容量重新分配数组以避免溢出。大多数系统语言在其标准库中提供了动态数组的实现(Rust、C++)。
步骤 1:从小开始,根据需要调整大小
按照我们的数组类比,缓解索引数量和大小之间权衡的第一步是,当索引的内存映射已满时动态调整索引的大小,在此过程中增加内存映射的容量。
在 Meilisearch 中,我们可以通过在索引映射已满时调整索引的大小来实现类似的行为。
我们在负责管理 Meilisearch 实例索引的索引调度程序中添加了此逻辑。它处理对索引的更改,例如新文档导入、设置更新等。特别是,我们更新了tick函数,该函数负责运行任务,以处理MaxDatabaseSizeReached 错误。顾名思义,当一批任务由于与索引关联的内存映射太小而无法容纳该批次期间执行的写操作的结果而失败时,就会返回此错误。
了解我们如何在 Rust 中实现这一点
// When you get the MaxDatabaseSizeReached error:
// 1. identify the full index
// 2. close the associated environment
// 3. resize it
// 4. re-schedule tasks
Err(Error::Milli(milli::Error::UserError(
milli::UserError::MaxDatabaseSizeReached,
))) if index_uid.is_some() => {
// Find the index UID associated with the current batch of tasks.
let index_uid = index_uid.unwrap();
// Perform the resize operation for that index.
self.index_mapper.resize_index(&wtxn, &index_uid)?;
// Do not commit any change we could have made to the status of the task batch, since the batch failed.
wtxn.abort().map_err(Error::HeedTransaction)?;
// Ask the scheduler to keep processing,
// which will cause a new attempt at processing the same task,
// this time on the resized index.
return Ok(TickOutcome::TickAgain(0));
}通过调整索引的大小来处理错误。它在IndexMapper::resize_index 函数中实现,该函数的简化实现如下所示
/// Resizes the maximum size of the specified index to the double of its current maximum size.
///
/// This operation involves closing the underlying environment which can take a long time to complete.
/// Other tasks will be prevented from accessing the index while it is being resized.
pub fn resize_index(&self, rtxn: &RoTxn, uuid: Uuid) -> Result<()> {
// Signal that will be sent when the resize operation completes.
// Threads that request the index will wait on this signal before reading from it.
let resize_operation = Arc::new(SignalEvent::manual(false));
// Make the index unavailable so that other parts of code don't accidentally attempt to open it while it is being resized.
let index = match self.index_map.write().insert(uuid, BeingResized(resize_operation)) {
Some(Available(index)) => index,
_ => panic!("The index is already being deleted/resized or does not exist"),
};
// Compute the new size of the index from its current size.
let current_size = index.map_size()?;
let new_size = current_size * 2;
// Request to close the index. This operation is asynchronous, as other threads could be reading from this index.
let closing_event = index.prepare_for_closing();
// Wait for other threads to relinquish the index.
closing_event.wait();
// Reopen the index with its new size.
let index = self.create_or_open_index(uuid, new_size)?;
// Insert the resized index
self.index_map.write().unwrap().insert(uuid, Available(index));
// Signal that the resize operation is complete to threads waiting to read from the index.
resize_operation.signal();
Ok(())
}如您所见,实现变得更加复杂,因为索引可以随时由其他具有读访问权限的线程请求。但是,从核心上讲,实现类似于动态数组的容量增加。
在这个新方案中,索引一开始会以很小的尺寸创建——比如,几个 GB——并在需要更多空间时动态调整大小,让我们能够解决上面提到的两种竞争用例。
我们本可以就此收手回家(好吧,技术上来说不行,因为我们是在 远程工作,但这无关紧要),但这种解决方案仍然存在两个问题。
- 如果我们想要同时处理两种用例,即拥有大量索引和大尺寸索引呢?
- 由于我们依赖于
MaxDatabaseSizeReached错误来判断索引是否需要调整大小,因此我们会丢弃批处理到目前为止所做的所有进度。这意味着要在调整大小的索引上重新开始,基本上会延长索引操作的持续时间。
我们想知道如何解决这些问题。在下一节中,我们将看到我们如何处理这个问题,以及进一步迭代引入的新边缘案例。
步骤 2:限制同时打开的索引数量
解决上述问题的首要步骤是找到一种方法来限制所有索引使用的总虚拟内存。我们的假设是,我们不应该同时将所有索引映射到内存中。通过将同时打开的索引数量限制为一个小数字,我们可以负担得起为每个索引分配大量虚拟内存。
这是使用具有以下特性的 简化 Least Recently Used (LRU) 缓存 实现的。
- 插入和检索操作是在线性时间内完成的,而不是通常的常数时间。考虑到我们存储的是数量很少的元素,这些元素的键具有高效的相等性比较函数(UUID),因此这并不重要。
- 它可以被多个读者访问而不会阻塞。在 Rust 术语中,这意味着数据结构是
Send和Sync,并且它的检索元素的函数接受一个共享引用 (&self)。通过将缓存放在一个RwLock后面,我们受益于此特性。 - 缓存使用一个代号来跟踪对项目的访问。查找项目只需要将它的代号提升到缓存已知的最新代号。当缓存已满时,驱逐项目是通过线性搜索缓存以查找最小的代号来完成的,这对应于最旧的访问项目。这种简单的实现不需要依赖
unsafe,这可以保护实现免受内存安全错误的风险。
使用此缓存,我们将同时打开的索引数量限制为例如 20 个。在 Linux 机器上,一个索引可以增长到 2 TB 才会耗尽虚拟空间。耗尽空间意味着总共 20 个索引的大小将以某种方式超过磁盘上的 128 TB,这在今天的标准中已经是相当多了,考虑到 2020 年 100 TB 的 SSD 售价为 40,000 美元。如果您遇到因累积打开的索引大小超过 128 TB 而导致的问题,请随时与我们联系 😎
如果我们从一个大的索引尺寸开始呢?
现在 LRU 允许我们在不限制索引总数的情况下容纳 2 TB 的内存映射,解决调整大小性能问题的简单方法是让所有索引都以 2 TB 的映射尺寸开始。请注意,创建 2 TB 的映射尺寸不会导致在磁盘上创建 2 TB 的文件,因为只有文档数量和索引数据量会导致磁盘文件增长。如果一个索引实际增长到超过 2 TB,调整大小机制将会在那里使其工作。但这仍然不太可能发生。由于缓存确保我们最多可以同时映射 20 个索引,我们可以拥有任意尺寸的索引,而无需支付任何调整大小的代价。
这种方案中唯一剩下的障碍是,对于某些操作系统来说,可用的虚拟地址空间远小于 128 TB。 一个问题 由一个用户在 v1.0 中甚至没有 500 GB 的虚拟内存来分配给单个索引而引起。为了解决这些边缘情况,以及 Windows 的问题(它只为进程宣传了 8 TB 的虚拟内存),我们决定在运行时测量我们可以内存映射的虚拟内存量。
我们找不到一种既快速又可移植的方法来实现这一点。我们决定利用 LMDB(我们用来存储索引的开源键值存储)提供的现有可移植性,以及我们堆栈中依赖于内存映射的部分。我们最终实现了对索引可以打开的最大映射尺寸进行二分搜索。
通过这种二分搜索,我们测量了在 Linux 上接近 93 TB 的实际分配预算,在 Windows 上介于 9 TB 和 13 TB 之间(这令人惊讶,因为这超过了宣传的数值!)。我们测量的 Linux 差异可以用虚拟地址空间在进程的所有分配之间共享,而不仅仅是环境映射来解释。由于分配需要连续,单个小分配会导致碎片并减少连续可用的虚拟内存。
二分搜索的实现可以在 IndexScheduler::index_budget 函数中找到。它计算可以同时打开多少个 2 TB 的索引,或者,如果可用空间少于 2 TB,则计算单个索引可以有多大。出于性能原因,如果至少可以映射 80 TB(Windows 为 6 TB),则会跳过这种二分预算计算,因为我们认为在这种情况下我们有足够的可用空间。
结论
索引数量与其最大尺寸之间的不幸权衡让我们从静态选择的最大索引尺寸切换到动态虚拟地址空间管理方案。Meilisearch 现在首先计算可以同时打开多少个 2 TB 的索引而不会溢出虚拟内存。然后,它使用一个 LRU 缓存,该缓存包含这么多使用 2 TB 映射尺寸打开的索引。这样一来,如果索引的尺寸超过了 2 TB 的限制,它就会被适当地调整大小。
我们不得不分两步进行此更改。首先,移除 --max-index-size CLI 选项,因为我们不想用 v1 来稳定它。然后,我们必须设计一个透明的方式,让用户在 v1.1 中管理索引。这是一个例子,说明了 v1 中的规划。
这项工作也受益于我们发布原型的全新流程,这使得像 newdev8 这样的仁慈的用户可以 帮助我们检查这些更改是否在其配置中生效。我们感谢他们的贡献 🤗
以下表格总结了本文讨论的各种虚拟地址空间管理方案。
| 方案 | 版本范围 | 索引最大尺寸 | 索引最大数量(Linux) | 支持小地址空间 | 索引调整大小 | 评论 |
|---|---|---|---|---|---|---|
--max-index-size |
v1.0 之前 | 在启动时定义 | 128 TB 除以 --max-index-size |
使用正确的参数值即可 | 从不 | 非直观的权衡 |
| 500 GB | v1.0.x | 500 GB | 大约 200 个 | 否 | 从不 | v1.0 的临时方案 |
| 索引调整大小,小索引尺寸 | prototype-unlimited-index-0 | 128 TB | 使用原始尺寸大约 12,000 个 | 是 | 频繁 | 性能下降 |
| 索引调整大小 + LRU,大索引尺寸 | v1.1.x 及以上 | 128 TB | 无限 | 是 | 对于小于 2 TB 的索引从不 | 当前“理想”解决方案 |
以下是 Meilisearch 中一些我们可以改进的现有限制,以便进一步改进该方案。
- 一个索引始终在 LRU 中使用一个槽位,无论其尺寸如何。对于大于 2 TB 的索引,这会导致分配错误。
- 当请求一个索引时,如果缓存已满,它会在驱逐任何索引之前被打开。这迫使我们为新打开的索引保留一个槽位,并且如果同时请求许多新的索引,可能会导致暂时的分配错误。
- 此实现需要代码,以便尽可能快地释放索引,并且在同一个任务期间不要两次打开给定的索引;如果未能遵守这一点,可能会导致死锁。
- 迭代所有索引的任务变慢了,尤其是在某些平台(macOS)上,这导致我们为其中一些任务添加了缓存(例如,请参见 此 PR)。
就这样吧!加入 /r/programming 上的讨论。
了解更多 Meilisearch 内容,请加入我们的 Discord 或订阅我们的 时事通讯。您可以在我们的 路线图 中了解更多关于我们产品的信息,并参与我们的 产品讨论。