

搜索栏是浏览网页不可或缺的一部分。无论我们是购物、欣赏音乐还是计划旅行,总有一个专用的搜索引擎在背后努力简化我们的生活。您是否曾经想过这些搜索引擎是如何工作的?在本文中,我们将深入探讨其中一个搜索引擎的内部工作原理:Meilisearch。
索引时间:从数据到文档
索引是一个基本过程,它包括收集、解析和存储数据以供后续检索。它在使搜索引擎能够提供快速且相关的结果方面发挥着至关重要的作用。
高性能存储引擎
Meilisearch 将数据存储为称为“文档”的离散记录,这些记录被分组到称为“索引”的集合中。在幕后,Meilisearch 使用 LMDB (Lightning Memory-Mapped Database) 键值存储,它在数据库应用程序中已被证明具有稳定性和广泛的应用。顾名思义,键值存储是将数据组织为键值对集合的存储系统。
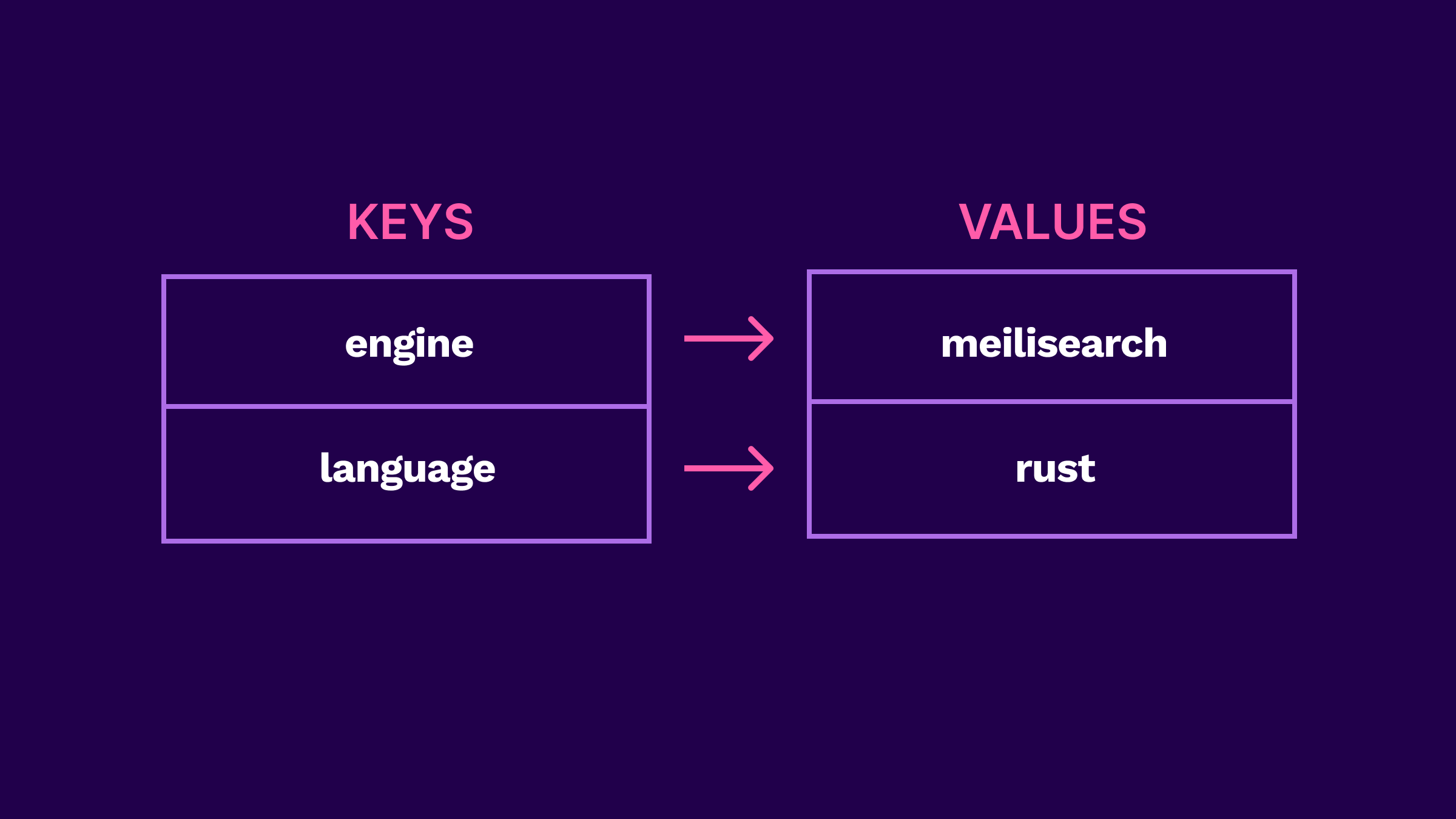
键值存储提供了灵活性和快速访问时间,并具有高效的性能,有助于用户快速响应的交互。LMDB 允许一次仅进行一个写入过程,从而避免了与同步相关的問題。因此,它使无限的并发读取器能够快速访问最新的、一致的数据。
在将数据存储到其键值存储之前,Meilisearch 必须对其进行彻底的预处理。这就是分词的用武之地。
从单词到词元
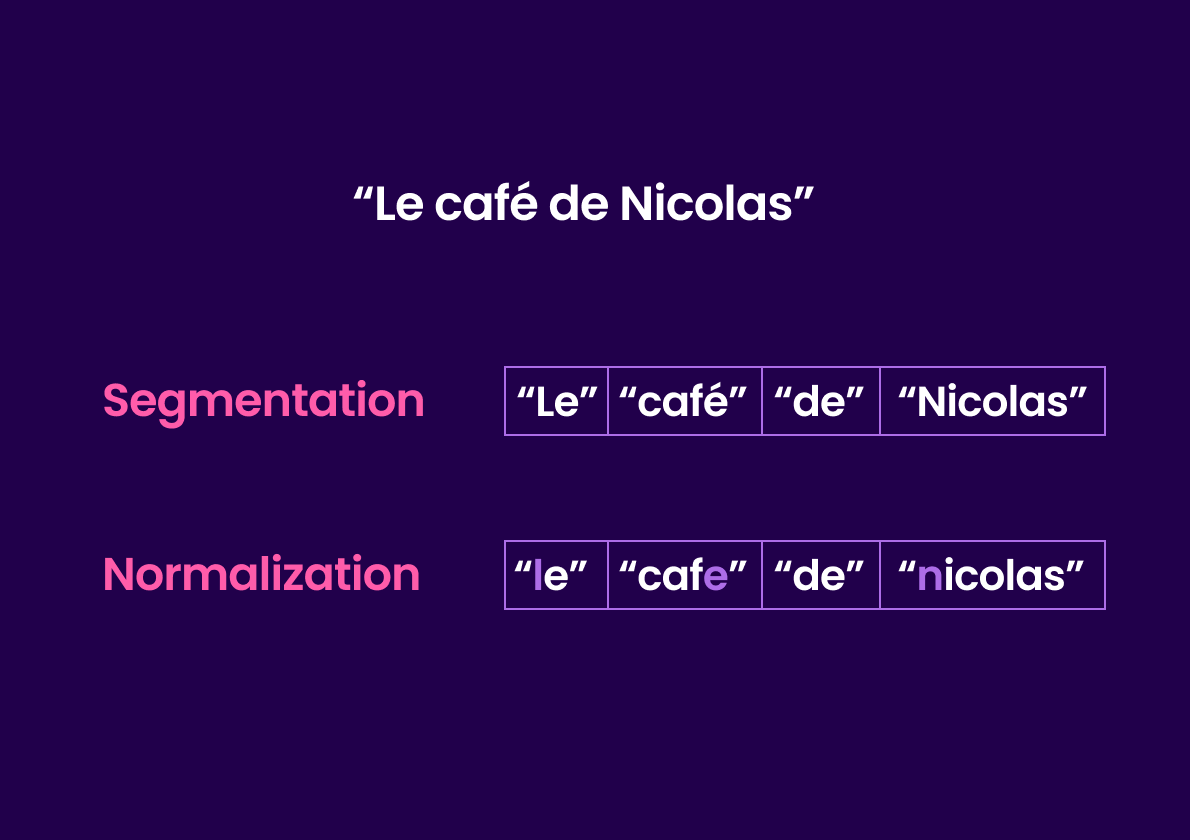
分词涉及两个主要过程:分段和规范化。
分段是指将句子或短语拆分为称为词元的更小的单位。
Meilisearch 使用(并维护)名为 Charabia 的开源分词器。分词器负责从文档字段中检索所有单词(或词元)。
接下来是规范化。单词根据每种语言的特性进行规范化。对于像法语这样的罗曼语,这个过程包括将单词设置为小写字母并删除重音符号,例如重音。例如,像“Le café de Nicolas”这样的句子会转换为“le cafe de nicolas”。
在对单词进行分段和规范化之后,引擎需要对其进行分类。使用适当的数据结构来组织词元对于性能至关重要。这将在以后允许快速检索最相关的搜索结果。
存储词元
像 Meilisearch 这样的现代全文搜索引擎具有前缀搜索、容错和地理搜索等功能。每个数据结构都有其自身的优缺点。在设计搜索引擎时,我们的团队仔细选择了最适合启用这些功能而不影响速度的数据结构。
在本节中,我们将探讨哪些数据结构为 Meilisearch 提供动力。
倒排索引
首先,我们需要谈谈倒排索引。毫无疑问,它是数据结构中最重要的一个。Meilisearch 使用它在搜索时快速返回文档。
倒排索引将文档中的每个单词映射到包含该词的文档集,以及其他信息,如它们在文档中的位置。
![Given the following documents: { “id”: 1 "title": "Hello world!" }, { “id”: 2 "title": "Hello Alice!" }. The inverted index would look like this: "alice" -> [2], "hello" -> [1,2], "world" -> [1]](https://blog.meilisearch.org.cn/content/images/2023/06/Inverted-index-3.png)
通过将单词存储一次并将它们与包含它们的文档相关联,倒排索引利用了跨文档的词语冗余。得益于此,Meilisearch 不需要浏览所有文档来查找给定单词,从而实现更快的搜索。
Meilisearch 为每个文档索引创建大约 20 个倒排索引,使其成为实例数量最多的数据结构之一。事实上,为了提供即时搜索体验,引擎需要在索引时进行大量预计算:单词前缀、包含可过滤属性的文档等等。要更好地了解倒排索引的工作原理,请阅读有关索引最佳实践的更多信息。
Roaring 位图
Roaring 位图是压缩数据结构,旨在有效地表示和操作整数集。
Meilisearch 在其倒排索引中广泛使用 Roaring 位图来表示文档 ID。Roaring 位图提供了一种空间高效的方式来存储大型整数集并执行集合操作,例如并集、交集和差集。这些操作在根据文档与其他文档的关系来细化搜索结果方面起着至关重要的作用,允许根据这些关系包含或排除特定文档。
有限状态机转换器
有限状态机转换器 (FST) 是一种结构化数据表示,非常适合执行字符串匹配操作。它表示从最小到最大的状态序列,单词按字典顺序排列。
有限状态机转换器也称为词典,因为它包含索引中存在的所有单词。Meilisearch 依赖于两种 FST 的使用:一种用于存储数据集中的所有单词,另一种用于存储最常出现的前缀。
FST 有用是因为它们支持压缩和延迟解压缩技术,优化了内存使用和存储。此外,通过使用正则表达式等自动机,它们可以检索与特定规则或模式匹配的单词子集。此外,这使得能够检索以特定前缀开头的所有单词,从而实现快速、全面的搜索功能。
FST 凭借其紧凑的设计,具有比倒排索引更小的数据结构的额外优势。正如我们将在后面看到的那样,这有助于更快、更高效的读取操作。您可以在 这篇关于有限状态机转换器的综合文章中了解更多信息。
R 树
R 树是树的一种类型,用于索引多维或空间信息。Meilisearch 利用 R 树来为其地理搜索功能提供支持。
R 树将地理坐标与其所属文档的标识符相关联。通过以这种方式组织坐标,它使 Meilisearch 能够以显著的效率执行空间查询。这些查询允许用户找到附近的点、特定区域内的点或与其他空间对象相交的点。
搜索时间:查询处理
现代搜索体验只需要您开始键入就能获得结果。为了实现这种即时搜索体验,Meilisearch 预先计算了最常见前缀的列表。
为了容忍拼写错误,Meilisearch 使用有限状态机转换器与莱文斯坦算法结合使用。该算法计算莱文斯坦距离,可以理解为将一个字符串转换为另一个字符串的成本。换句话说,它量化了将一个单词转换为另一个单词所需的转换次数。
在莱文斯坦算法的背景下,可能的转换是
- 插入,例如 hat -> chat
- 删除,例如 tiger -> tier
- 替换,例如 cat -> hat
- 转置或交换,例如 scared -> sacred
FST 在指定编辑距离内生成一个单词的所有可能变体,使引擎能够计算莱文斯坦距离并通过将用户输入与有效单词字典进行比较来准确地检测拼写错误。
很明显,在处理搜索请求时需要考虑许多因素。用户是否已完成键入?查询中是否包含拼写错误?哪些文档应该在搜索结果中首先显示?
让我们讨论 Meilisearch 如何处理搜索查询以及如何细化和排序搜索结果。
查询图
每当收到一个搜索查询时,Meilisearch 就会创建一个查询图,表示查询及其可能的变体。
为了计算这些变体,Meilisearch 将连接和拆分算法应用于查询词。考虑的变体还包括可能的拼写错误和同义词——如果用户设置了它们。例如,让我们检查查询:the sun flower。Meilisearch 还会搜索以下查询
the sunflower:连接the sun flowed:替换the sun flowers:添加
现在考虑一个更复杂的查询:the sun flower is facing the su,查询图应如下所示
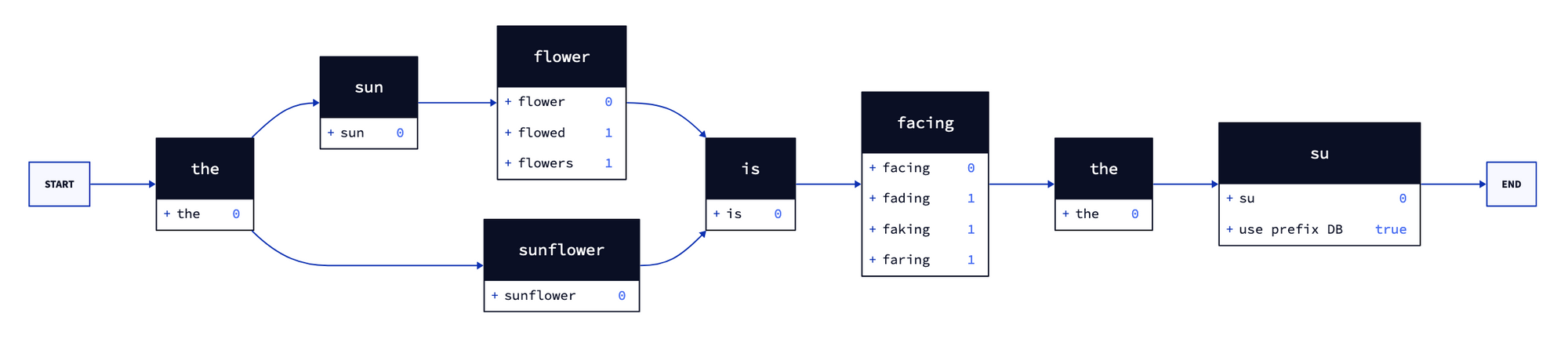
如上图所示,该图表示搜索查询的不同解释。引擎为每个查询词预先计算了词语变体(及其成本)。此外,它检测最后一个查询词是否是一个前缀(后面没有空格),从而表明需要查询前缀数据库。
那么引擎如何利用查询图呢?
正如我们之前所见,在索引过程中,Meilisearch 会识别所有具有可过滤属性的文档,例如genre。随后,它会生成一个与每个属性值相关的文档 ID 列表,例如comedy 或horror。首先,当应用过滤器时,Meilisearch 会将潜在结果缩小到满足过滤器条件的文档 ID。
接下来,它使用查询图中生成的查询词和变体,并在有限状态机转换器(即我们的词典)中搜索匹配的词。如果该词被认为是一个前缀,它也会在前缀 FST 中查找它。
当在 FST 中遇到单词时,它会在倒排索引中搜索这些单词(其中包含单词到文档 ID 的映射)以检索相应的文档 ID。
最后,引擎执行交集操作,以识别包含查询图中词语且满足筛选条件的文档。
让我们举个例子来更好地理解查询处理:假设你有一个歌曲数据集。搜索查询是 John Lennon。用户希望只检索 1957 年至 1975 年间发布的歌曲。
首先,Meilisearch 检索该时间范围内歌曲的文档 ID。然后,在 FST 中检查查询图中的词语是否存在后,Meilisearch 检索包含 John、Lennon 或二者的文档 ID。它还会检索可能的变体,但为了简单起见,我们在此示例中不包括它们。
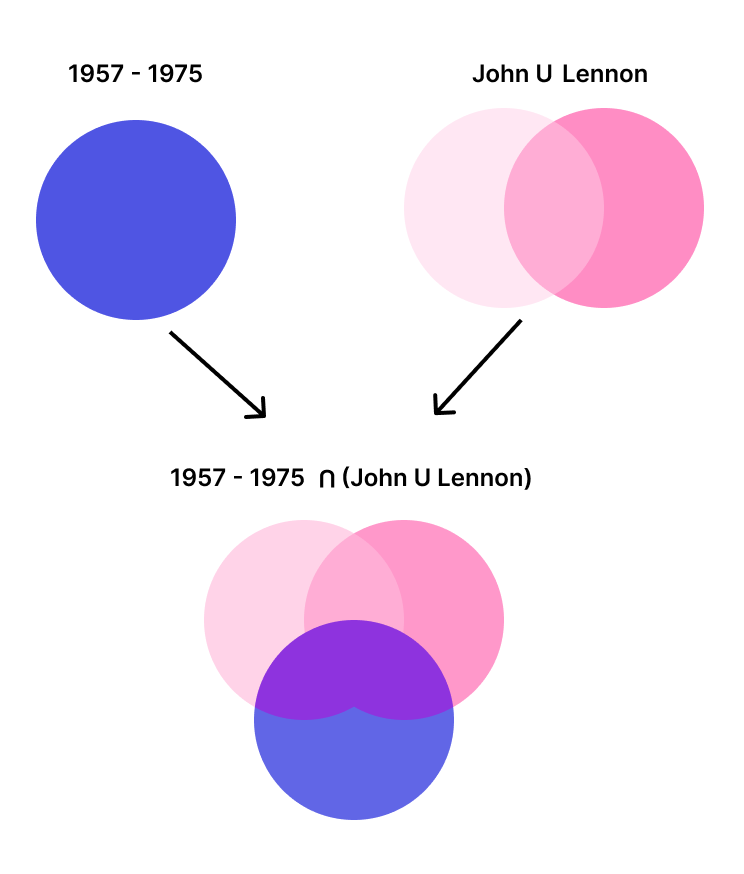
最后,对两个文档 ID 集合进行交集操作(图表中的紫色区域)。这意味着只保留同时出现在两个集合中的文档 ID。换句话说,Meilisearch 保留了 1957 年至 1975 年间发布的包含 John、Lennon 或二者的歌曲的文档 ID。
当多个文档匹配搜索查询时,引擎如何决定首先返回哪个文档?哪个更相关?让我们探索 Meilisearch 用于确定如何对结果进行排名规则。
相关性
正如我们之前讨论的,查询图包含词语的可能变体。因此,Meilisearch 还会将包含像 John Lebon 这样的艺术家的文档作为搜索结果的一部分返回。
幸运的是,查询图不仅考虑了词语的变体,还为它们分配了 Levenshtein 成本,这在其他因素中,帮助 Meilisearch 确定搜索结果的相关性。
Meilisearch 使用 桶排序 对搜索结果中的文档进行排序。此算法允许根据一组连续规则对文档进行排名。默认情况下,Meilisearch 按以下顺序优先考虑规则
- 词语:根据匹配的查询词语数量对文档进行排序,包含所有查询词语的文档排名第一
- 拼写错误:根据拼写错误的数量对文档进行排序,匹配查询词语且拼写错误更少的文档排名第一
- 邻近度:根据匹配的查询词语之间的距离对文档进行排序。查询词语彼此靠近且顺序与查询字符串相同的文档排名第一
- 属性:根据属性的排名顺序对文档进行排序。包含查询词语的更重要属性的文档排名第一。属性开头包含查询词语的文档比属性结尾包含查询词语的文档更相关
- 排序:如果处于活动状态,则根据查询时设置的用户定义参数对文档进行排序
- 精确度:根据匹配词语与查询词语的相似度对文档进行排序
Meilisearch 按顺序应用这些规则,逐步对结果进行排序。如果两个文档在应用一项规则后仍然相同,它将使用下一条规则来打破平局。
默认情况下,Meilisearch 每次搜索返回最多 1000 个文档,优先考虑提供最相关的结果,而不是所有匹配的结果。换句话说,Meilisearch 优先考虑效率和相关性,而不是详尽的结果,以确保最佳的搜索体验。
结论
搜索引擎是包含多个相互关联的组件的复杂系统,它们协同工作以提供无缝的搜索体验。虽然不同搜索引擎的内部工作机制可能有所不同,但我们已经探讨了现代搜索引擎背后的底层机制。
Meilisearch 目前正在探索 语义搜索 的广阔领域。AI 驱动的搜索正在重塑我们理解查询和文档的方式,开辟了新的可能性和用例。如果你渴望亲身体验它,我们邀请你尝试我们的 向量搜索原型——你的反馈将非常宝贵!
Meilisearch 是一个开源搜索引擎,它不仅为最终用户提供最先进的体验,而且还提供简单直观的开发人员体验。你想看看 Meilisearch 的实际效果吗?试试我们的 演示。你也可以 在本地运行它 或在 Meilisearch 云 上创建一个帐户。
要了解有关 Meilisearch 的更多信息,你可以在 Discord 上加入社区或订阅 时事通讯。你可以通过查看 路线图 和参与 产品讨论 来了解更多关于该产品的信息。