

这是博客文章系列的第 4 部分,最初发布在克莱门特·雷诺的博客上。 从 第 1 部分、第 2 部分 和 第 3 部分 开始你的旅程。 这篇博文假设你已经阅读了第 1 部分和第 2 部分。
在这篇博文中,我们将讨论如何在 Arroy 中实现增量索引。 增量意味着当在树中插入或删除项目时,我们可以只更新所需部分,而不是重建所有内容。
在 Meilisearch,这一点至关重要,因为我们的用户通常会定期发送更新,他们的内容也会不断变化。 从头开始重建所有内容非常昂贵,而且不会带来良好的体验; 这就是为什么我们在最新版本中已经花了大量时间来让所有的 数据结构支持增量索引 ,arroy 也是其中之一,我们 必须 也实现它!
理论
以下模式显示了将文档添加到现有树中以及从现有树中删除文档时应发生的事情的高级视图。
提醒一下,arroy 是一个基于 LMDB 的向量存储,LMDB 是一种嵌入式事务性内存映射键值存储。 它将你的向量存储在由三种类型的节点组成的树中
- 拆分节点 - 存储有关哪些项目 ID 分布在其左右两侧的信息。
- 后代节点 - 存储多个项目 ID。
- 项目 - 单个向量。
对于以下示例,我们将考虑后代节点不能包含 超过 两个项目,并且 ID 越接近,项目在空间中的距离就越近。 例如,项目 1 与项目 2 相近,但距离项目 10 更远。
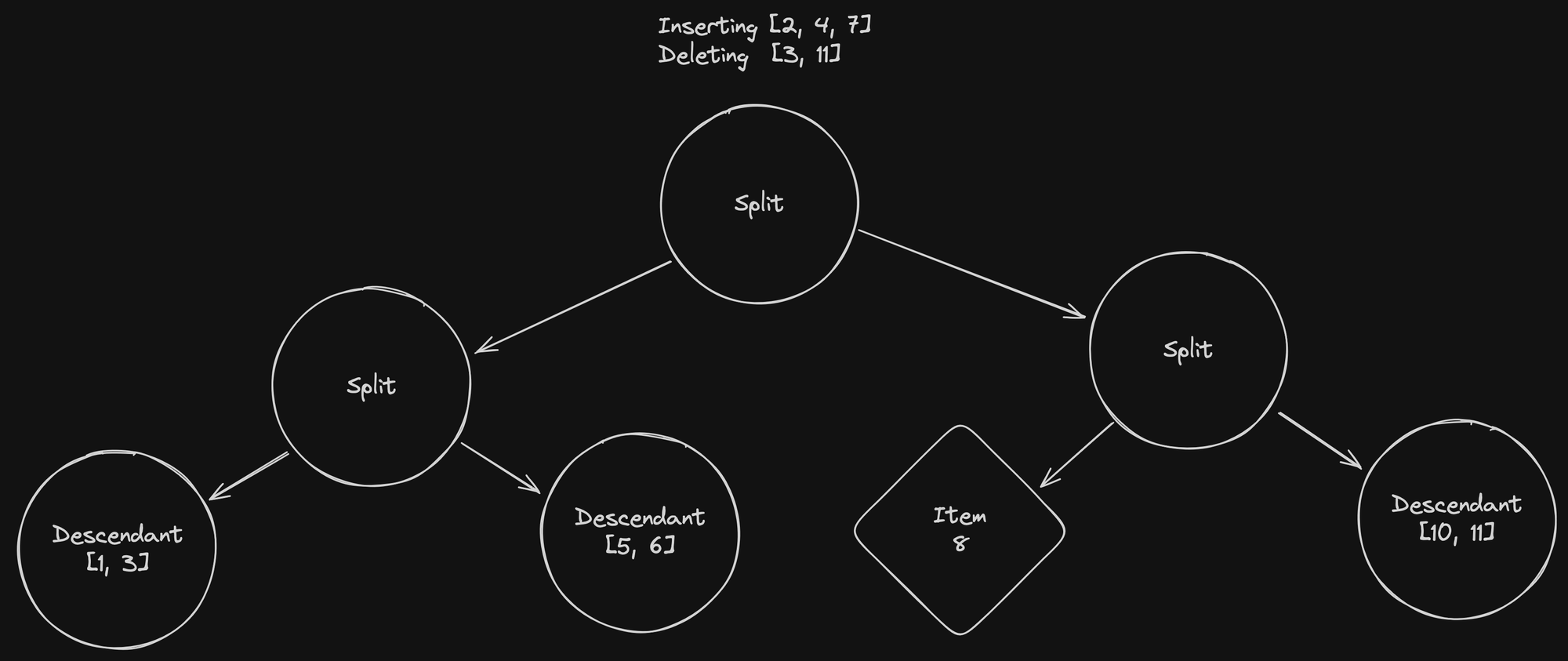
这里,我们试图插入项目 2 和 7 ,并删除项目 3 和 11。
按照我们在搜索中所做的,我们将要插入的项目拆分到左右拆分节点之间。 但是已删除的项目不再存在于数据库中! 我们没有它们关联的向量,因此我们需要遍历所有叶子来查找和删除它们。
幸运的是,由于我们使用的是咆哮位图,因此此列表不会占用太多内存,而且由于我们从未更新它,因此我们可以将其与每个线程共享,而无需复制它 🎉
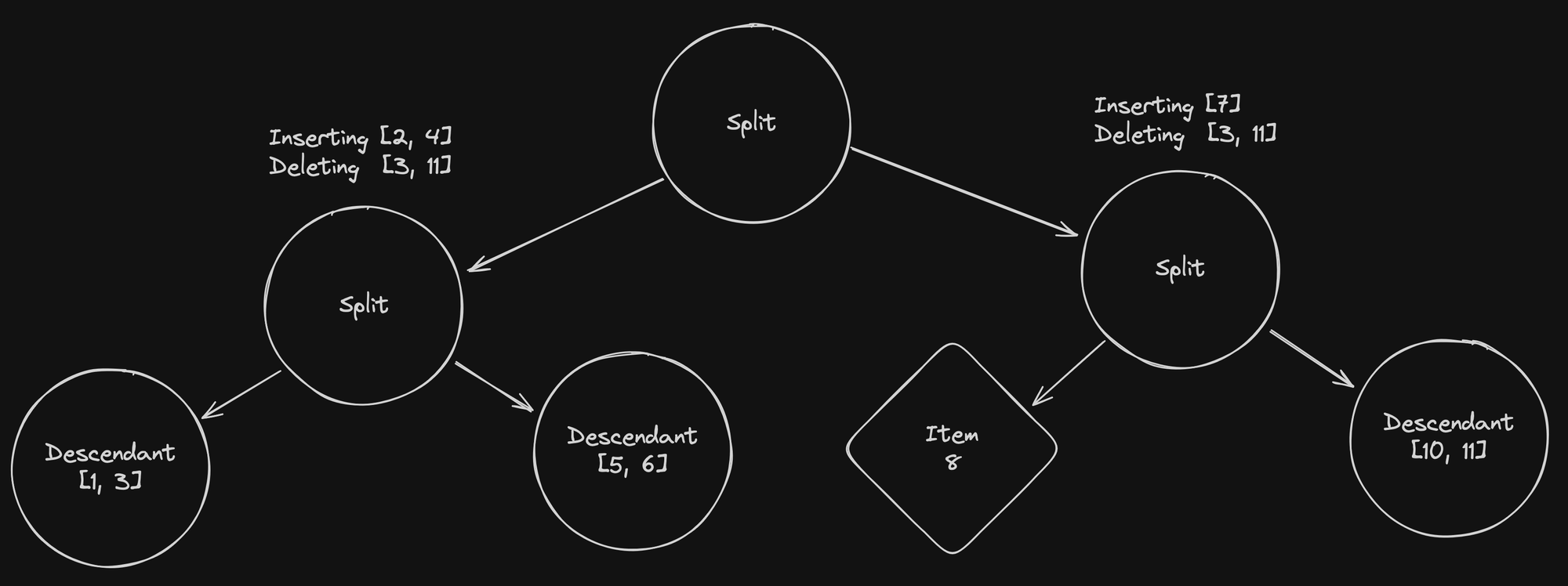
请注意如何将要插入的项目在左右拆分节点之间平衡。 在下一步中,我们将遵循相同的过程,并将要插入的两个项目列表都拆分到拆分节点上。
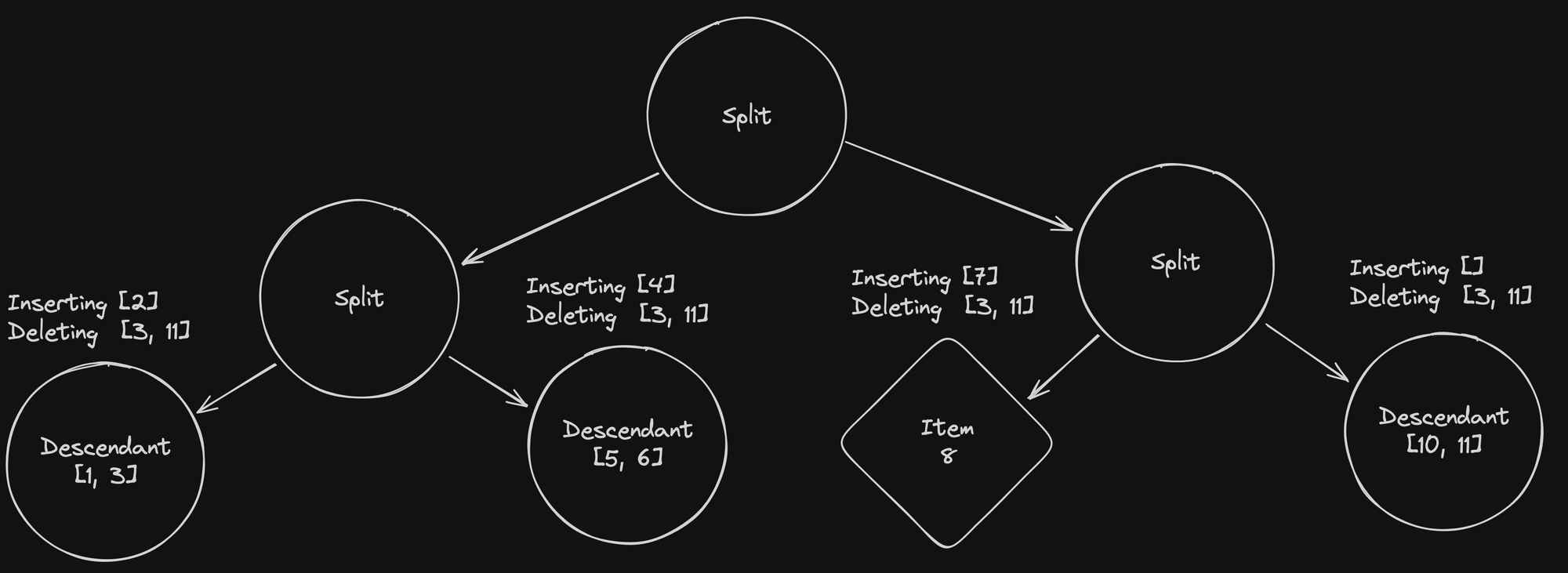
正是这一步发生了所有好事。 从左到右
- 第一个后代节点删除了其项目
3,并添加了项目2。 - 第二个后代节点变得太大,必须被一个新的拆分节点取代。
- 项目
8成为一个后代,包含项目7和8。 - 在删除最后一个后代节点中的项目
10之后,我们将其替换为指向项目的直接链接,以减少树中的节点数量(并通过减少查找次数来提高搜索时间)。
现在你已经看到了增量索引过程的所有步骤,我们还是要对发生的事情做一些记录
- 在前三个步骤中,我们必须读取所有树节点,默认情况下,这等于数据库中的项目总数。
- 在最后一步中,我们必须写入四个新的树节点。 以前我们必须重写整个树。 写入次数(这是数据库中最慢的操作)减少到最低限度。
- 该过程在单个树上运行,这意味着我们仍然可以多线程计算每棵树。
- ID 现在不再是连续的,这与在 并行写入树 中描述的 ID 生成策略不兼容。
我们如何修复 ID 生成?
在索引过程开始时,我们需要收集所有现有的树 ID。
我们需要生成新节点的信息是
- 树节点总数,用于知道何时停止构建树。
- 我们要重用的已用 ID 中的“空洞”。 这种碎片是在我们编辑树时产生的。
- 树中存在的最高 ID,用于生成下一个新 ID。

这个“简单”的想法是为树节点总数设置一个计数器。 一个我们可以递增以生成新的新鲜 ID 的计数器。 最具挑战性的部分是在线程之间选择一个可用的 ID,并且不使用大型互斥锁。
我花了一些时间才找到解决最后一点的方法; 我实现了一个非常复杂的解决方案(150loc),最终 从头开始重写 ,在一个小时内就得到了一个简单高效的解决方案。 我们将了解在找到最终解决方案之前经历的所有想法。
共享可用的 ID 的迭代器
第一个也是最直接的想法是创建并共享所有可用 ID 的迭代器。
let mut available_ids = available_ids.into_iter();
roots.into_par_iter().for_each(|root| {
// stuff
let next_id = available_ids.next();
// stuff
});如果你熟悉 Rust,你会立即注意到 for_each 不能捕获对 available_ids 的可变引用,因为我们使用的是 Rayon 的 into_par_iter 方法,该方法以多线程方式在迭代器上执行下一个方法。 这意味着我们无法调用 .next()。
通过使用互斥锁(互斥的简称 互斥),我们可以使其编译
let mut available_ids = Mutex::new(available_ids.into_iter());
roots.into_par_iter().for_each(|root| {
// stuff
let next_id = available_ids.lock().unwrap().next();
// stuff
});这是安全的,并将产生正确的结果,但随着所有线程必须在锁上相互等待,因此无法很好地扩展。
让每个线程拥有自己的 ID 列表
当你需要删除一个锁时,一个常见的解决方案是在事先将工作拆分,以便每个线程都可以充分发挥其能力,而无需知道其他线程在做什么。 这就是 我最初实现的解决方案。 想法是将咆哮位图爆炸成与要更新的树一样多的较小的咆哮位图。
以下函数可以将咆哮位图拆分为 n 个大小相等的子位图
pub fn split_ids_in(available: RoaringBitmap, n: usize) -> Vec<RoaringBitmap> {
// Define the number of elements per sub-bitmap
let chunk_size = available.len() / n as u64;
let mut ret = Vec::new();
let mut iter = available.into_iter();
for _ in 0..(n - 1) {
// Create a roaring bitmap of `chunk_size` elements from the iterator without consuming it
let available: RoaringBitmap = iter.by_ref().take(chunk_size as usize).collect();
ret.push(available);
}
// the last element is going to contain everything remaining
ret.extend(iter);
ret
}有了这个可用的函数,然后就可以使用 Rayon 的并行迭代器的 zip 方法轻松使用每个树的位图进行更新
let available_ids = split_ids_in(available_ids, roots.len());
roots.into_par_iter().zip(available_ids).for_each(|(root, available_ids)| {
let mut available_ids = available_ids.into_iter();
// stuff
let next_id = available_ids.next();
// Here, we can use the available_ids without any locks or inter-thread synchronization
// stuff
});当我们更新已存在的根树时,这很好用。 但稍后,我们可能想从头开始创建新的树,而且我们无法事先知道需要创建多少棵新树。 这是一个问题,因为如果没有这些信息,我们就不知道需要创建多少个子位图。
此时,我无法看到解决这个问题的简单方法,但我假设我们很少创建大量新的树,而且所有新的树都会使用大量 ID。 这意味着,将所有 ID 都提供给 第一个 新的树 可能会奏效(在没有生产环境监控的情况下,很难 100% 确定)。
最终解决方案
之前的解决方案很复杂,甚至无法完美运行。 当我在滚动咆哮位图的文档时,我看到了 select 方法 ,并立即明白了如何使最初的方法起作用。
此方法允许你以高效的方式按索引获取位图中的值。
例如,如果位图中包含以下值: 13, 14, 15, 98, 99, 100
select(0)返回13。select(3)返回98。select(5)返回100。select(6)返回None。
考虑到这一点,如果我们以 只读 方式与所有线程共享位图,并将位图中的索引作为原子数字共享,那么我们可以让多个线程同时获取可用 ID,并实现无锁同步。
一旦 select 方法返回 None,就意味着我们可以停止从位图中获取 ID,而是直接使用旧方法从头开始生成新的 ID。
即使它非常快,调用 select 方法仍然需要一些时间,因此,一旦一个线程从该方法返回 None,我们就会更新一个原子布尔值,告诉我们位图中是否还有值可供查看。 如果没有,我们可以跳过调用 select ,并直接生成一个新的 ID。
考虑到这一点,我们在第 2 部分中向你展示的酷炫的 ConcurrentNodeIds 结构变得更加复杂,但它仍然让我们能够在没有任何锁的情况下公平地生成 ID!
/// A concurrent ID generator that will never return the same ID twice.
pub struct ConcurrentNodeIds {
/// The current tree node ID we should use if no other IDs are available.
current: AtomicU32,
/// The total number of tree node IDs used.
used: AtomicU64,
/// A list of IDs to exhaust before picking IDs from `current`.
available: RoaringBitmap,
/// The current Nth ID to select in the bitmap.
select_in_bitmap: AtomicU32,
/// Tells if you should look in the roaring bitmap or if all the IDs are already exhausted.
look_into_bitmap: AtomicBool,
}
impl ConcurrentNodeIds {
/// Creates an ID generator returning unique IDs, avoiding the specified used IDs.
pub fn new(used: RoaringBitmap) -> ConcurrentNodeIds {
let last_id = used.max().map_or(0, |id| id + 1);
let used_ids = used.len();
let available = RoaringBitmap::from_sorted_iter(0..last_id).unwrap() - used;
ConcurrentNodeIds {
current: AtomicU32::new(last_id),
used: AtomicU64::new(used_ids),
select_in_bitmap: AtomicU32::new(0),
look_into_bitmap: AtomicBool::new(!available.is_empty()),
available,
}
}
/// Returns a new unique ID and increases the count of IDs used.
pub fn next(&self) -> Result<u32> {
if self.look_into_bitmap.load(Ordering::Relaxed) {
let current = self.select_in_bitmap.fetch_add(1, Ordering::Relaxed);
match self.available.select(current) {
Some(id) => Ok(id),
None => {
self.look_into_bitmap.store(false, Ordering::Relaxed);
Ok(self.current.fetch_add(1, Ordering::Relaxed))
}
}
} else {
Ok(self.current.fetch_add(1, Ordering::Relaxed))
}
}
}实际性能
我还没有进行过很多基准测试(不过我很想做,并且可能会在以后更新这篇文章),但在对几十万个项目进行的基准测试中,我得到了以下结果
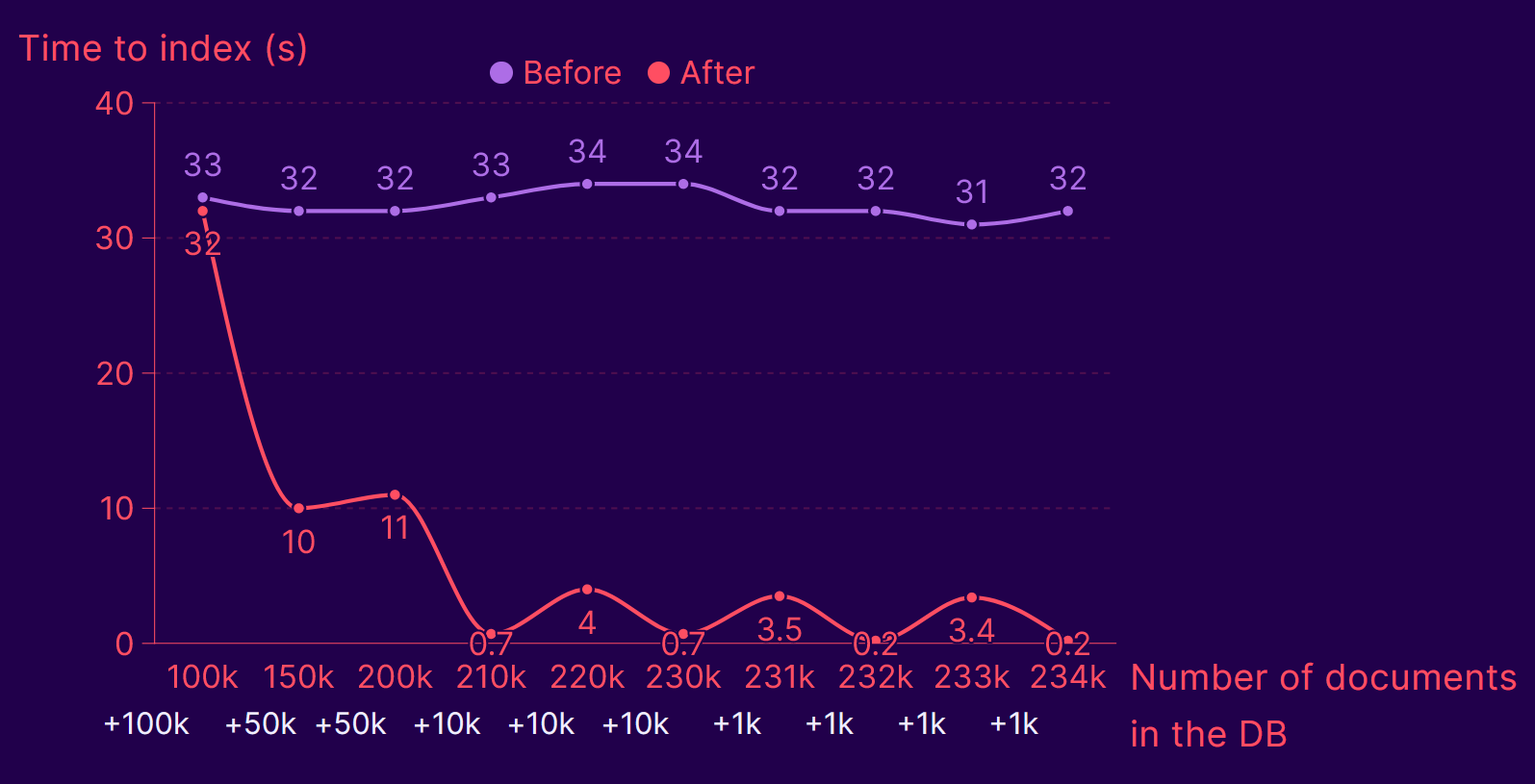
- 平均而言,在索引了三批项目之后,我们的速度提高了 10 倍以上。
- 我们之后观察到的让速度从约 700 毫秒下降到约 3 秒的小幅波动是由于随着项目数量的增加而创建了新的树。
- 我预计这个基准测试代表了一个最坏的情况
- 我所有的项目 ID 都是随机生成的,这意味着重复/更新很少,但总是新增插入,并且写入次数更多。
- 我的向量也是用均匀分布随机生成的,这意味着我们应该不会像在现实生活中的数据集中那样观察到聚类。
此功能现在已在包含数百万文档的生产数据中使用,我们已经看到在包含 200 万个项目的数据库中,在不到一分钟的时间内添加了 9000 个项目的数字。
Meilisearch 是一个开源搜索引擎,使开发人员能够构建最先进的体验,同时享受简单直观的开发人员体验。
有关 Meilisearch 的更多信息,你可以加入 Discord 上的社区,或订阅 时事通讯。 你可以通过查看 路线图 并参与 产品讨论 来详细了解产品。