

这是博文系列的第 2 部分最初发表在我的个人博客上。从第 1 部分开始旅程。
展示一个单线程、内存映射的键值存储如何比手工编写的内存映射解决方案更高效,不是很好吗?在将 Spotify 基于磁盘的近似最近邻库移植到 Rust,更具体地说是移植到 LMDB 时,我遇到了问题。这些问题主要归因于 LMDB 和内存安全。以下就是故事。
为了提醒您,Arroy 是一个将嵌入(浮点数向量)存储在磁盘上的库。在这些向量之上会生成一些数据结构,这些数据结构看起来像是由法线控制的树,用于递归地将向量数据集划分为子域。但您可以阅读更多关于此内容的信息,在 本系列的第 1 部分 中。
Annoy 如何生成树节点?
Annoy,Spotify 库将节点存储在磁盘上,包括项目节点(包含嵌入的节点)和我们将在此文中称为树节点的其他节点。这样做的优势是双重的
- 程序的内存使用率很低,并且通过操作系统进行了优化,因为所有节点都驻留在一个内存映射文件中。
- 这个概念很简单:通过使用节点 ID 访问节点。库将使用简单的乘法来找到其在磁盘上的偏移量。
但是,这样做也有一些缺点。所有节点:包含嵌入的项目以及树节点必须具有相同的尺寸,如果用户想要使用 ID 231 识别其嵌入,库将将文件大小增加到 ID 乘以节点大小。例如,对于一个 768 维的向量,存储一个具有 ID 231 的单个项目将生成一个超过 6.5 TiB 的文件。
在生成最终数据结构时,所有树节点都与包含嵌入的用户项目一起写入同一个文件中。这些树构建过程并行运行,每个树运行一个进程,因此在定义新创建的节点 ID 和为其保留的内存区域时需要大量同步,最重要的是,当内存映射文件太小而无法接受更多节点时,只有一个线程必须扩展文件,因此在可变内存映射和变量周围使用互斥锁。树生成的一个有趣的特性是生成过程只需要包含嵌入的原始用户项目。
我们将它移植到 LMDB 时遇到的挑战
有趣的是,这是我很久以来第一次编写 C++ 代码,也是我第一次请 ChatGPT 为我编写代码,因为我对编写 C++ 代码没有信心,害怕出现段错误。我需要一个小程序从标准输入中反序列化嵌入并将其提供给 Annoy。ChatGPT 生成的代码大多有效,但它遗漏了一个至关重要的 空向量检查,这导致了段错误...
将它移植到 LMDB 的主要障碍是,向这个键值存储写入是单线程的。它不支持并发写入操作,以维护正确平衡的 B 树。有趣的事情来了!
从不同线程读取用户项目节点
我们从一开始就在 Meilisearch 中使用 LMDB。它是一个维护良好的键值存储,在 Firefox 中使用,并由 OpenLDAP 开发人员维护。它是内存映射的,不维护内存中的用户端条目缓存,而是向您提供指向磁盘上内存映射区域的指针。主要优势在于,只要您的读取事务存在,您就可以保留指向该区域的指针。太棒了!因为它也是一个支持原子提交的事务性键值存储!
但是树生成不需要引用生成的节点,只需要用户项目即可。我们之前看到,LMDB 直接提供指向内存映射文件的指针,而不维护任何中间缓存(该缓存可能会失效)。LMDB 还存在另一个怪癖:您无法在多个线程之间共享只读事务,即 RoTxn: !Sync,并且您无法在线程之间移动写入事务,即 RwTxn: !Send + !Sync。哦!而且无法在未提交的更改上创建读取事务。这是一个问题,因为我们希望在存储项目的同一个事务中生成数据结构树。
但是魔法无处不在,从以下简单而有趣的数据结构开始。原理是将指向包含嵌入的内部用户项目的指针保存在 Vec<*const u8> 中。感谢 Rust,我们可以在编译时确保指针的生存期足够长,方法是将生存期保留在结构体中。使用 &'t RwTxn 获取 &'t RoTxn,方法是使用 Deref,也确保我们无法在使用 &'t mut RwTxn 读取时修改数据库。 根据 LMDB 的主要开发者,在线程之间共享这些指针是安全的,这就是为什么我为这个结构实现了 Sync。
pub struct ImmutableItems<'t, D> {
item_ids: RoaringBitmap,
constant_length: Option<usize>,
offsets: Vec<*const u8>,
_marker: marker::PhantomData<(&'t (), D)>,
}
impl<'t, D: Distance> ImmutableItems<'t, D> {
pub fn new(rtxn: &'t RoTxn, database: Database<D>, index: u16) -> heed::Result<Self> {
let mut item_ids = RoaringBitmap::new();
let mut constant_length = None;
let mut offsets = Vec::new();
for result in database.items()? {
let (item_id, bytes) = result?;
assert_eq!(*constant_length.get_or_insert(bytes.len()), bytes.len());
item_ids.push(item_id);
offsets.push(bytes.as_ptr());
}
Ok(ImmutableLeafs { item_ids, constant_length, offsets, _marker: marker::PhantomData })
}
pub fn get(&self, item_id: ItemId) -> heed::Result<Option<Leaf<'t, D>>> {
let len = match self.constant_length {
Some(len) => len,
None => return Ok(None),
};
let ptr = match self.item_ids.rank(item_id).checked_sub(1).and_then(|offset| self.offsets.get(offset)) {
Some(ptr) => *ptr,
None => return Ok(None),
};
let bytes = unsafe { slice::from_raw_parts(ptr, len) };
ItemCodec::bytes_decode(bytes).map(Some)
}
}
unsafe impl<D> Sync for ImmutableItems<'_, D> {}您可能还注意到这个简化版数据结构中的一些其他有趣的优化。我们还知道用户项目节点的长度是固定的,因此我决定只存储它一次,将偏移量向量的尺寸减少一半。考虑到我们的目标是存储 100M 个向量,并且该向量位于内存中,我们将其大小从 1526 MiB 缩小到 763MiB,虽然不多,但聊胜于无。
并行写入树节点
好了!现在我们知道如何存储指向项目的指针,并在线程之间共享它们,而无需任何用户端同步,我们需要使用它来生成树节点。我们已经知道如何在 Meilisearch 中处理 LMDB,并决定实施相同的解决方法。要并行写入 LMDB,请写入不同的独立文件,然后将所有内容合并起来。这利用了 无共享架构原则,并将算法隔离开。这极大地减少了同步点的数量 与原始 C++ 代码相比 (查看 .lock/unlock 调用)到我们代码中的一行:原子递增的全局树节点 ID。
pub fn next_node_id(&self) -> u64 {
self.0.fetch_add(1, Ordering::Relaxed)
}我们基于用户项目节点生成普通分割节点的函数现在只是将节点写入独立的文件。 节点被追加到文件中,磁盘偏移量和边界存储在向量中,每个节点一个 usize。使用 Rayon,我们并行运行所有树生成函数,并在完成后,检索文件和边界,将唯一识别的节点顺序写入 LMDB。
性能比较
我们在 Meilisearch 的目标是支持大约 768 维的 100M 个嵌入。如果我们将它们存储为 f32 向量,没有任何 降维,这将相当于 100M * 768 * 4 = 307B,换句话说,存储原始向量需要 286 GiB,没有任何内部树节点,即无法有效地搜索它们。
如果您没有指定要生成的树的数量,该算法将继续创建树,直到树节点的数量小于项目向量的数量。最后,树节点的数量和项目数量应该大致相同。
发现我们可以索引的向量限制
Arroy 和 Annoy 广泛使用内存映射,但方式略有不同。在 @dureuill 的上一篇文章中,我们看到 操作系统没有无限的内存映射空间。因此,让我们深入了解一下性能结果。
我在使用 Arroy 处理 25M 个 768 维的向量时发现了一些奇怪的事情。CPU 没有被使用,程序似乎大量读取 SSD/NVMe,太多 🤔 树生成算法将向量空间分割为具有更少向量的子域。但是,它必须首先找到合适的法线来分割整个域,为此,它会随机选择许多项目。不幸的是,我的机器只有 63 GiB 的内存,索引这些 25M 个项目需要超过 72 GiB。Annoy 也遇到了同样的问题。
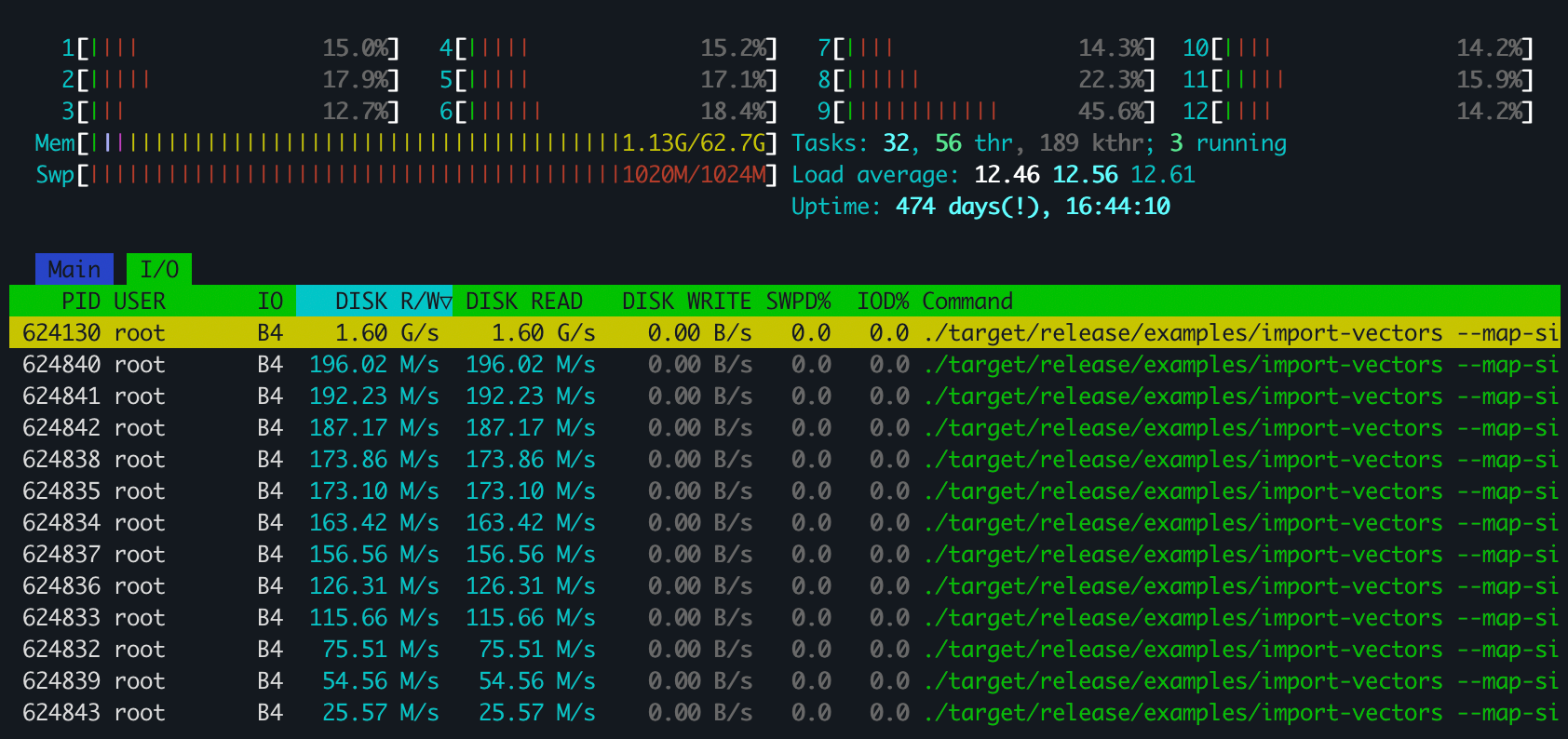
经过调查,我明白了为什么整个交换空间和内存映射限制都被触及了。不仅项目节点不仅是 768 * 4 字节,因为我们在向量旁边存储了范数和其他内容,而且在 Arroy 的情况下,LMDB 需要维护条目周围的 B 树数据结构,这些数据结构也占用内存映射空间。这两个程序都请求内存中不可用的随机项目节点,因此操作系统会从磁盘中获取它们,这需要时间。哦,并且每个线程都并行地这样做。CPU 只是在等待磁盘。
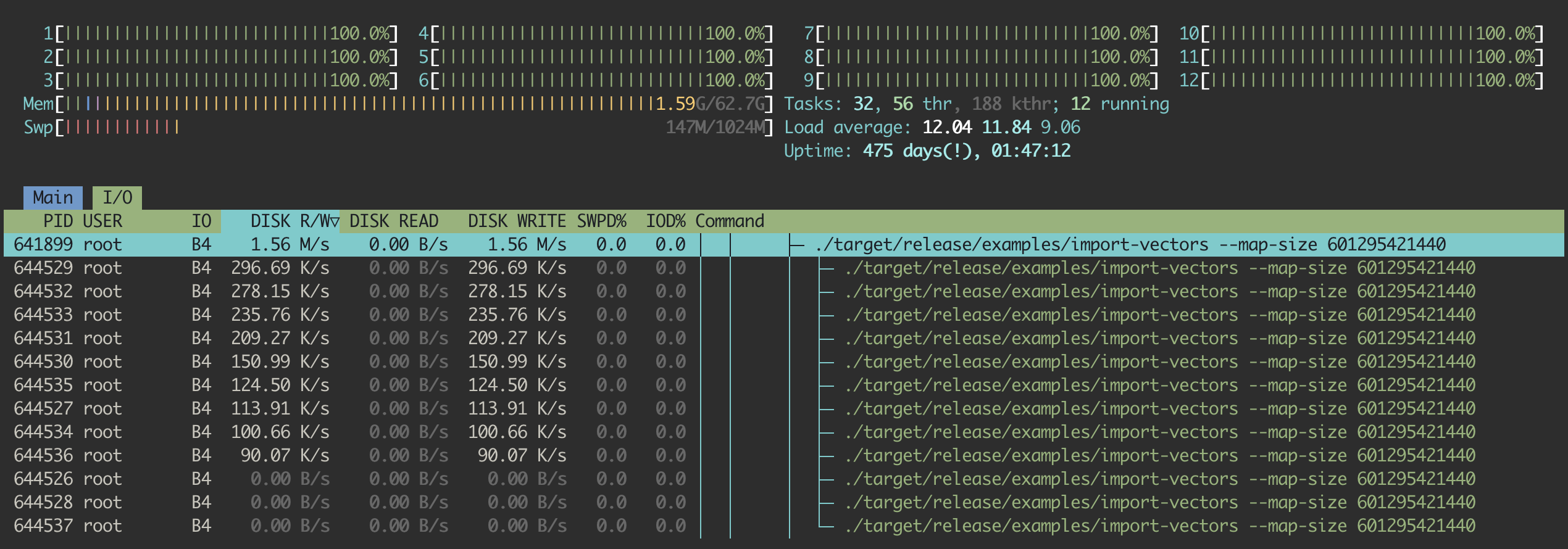
因此,经过一些二分查找,我找到了 arroy 成功使用所有内存而没有受到磁盘速度限制的点。它可以在一台 63 GiB 的机器上索引 15.625M 个向量。您可以从这个 htop 截图中看到,磁盘读取速度为零,因为所有向量都适合放入 RAM 中,arroy 正在将树节点写入磁盘,并且 CPU 正在尽力工作。处理这些内容花费了不到 7 个小时。
但是... Annoy 无法索引相同数量的文档。它遇到了之前我们看到过的问题:磁盘读取量高,CPU 使用率低。但为什么呢?我需要澄清,因为节点的格式相同,要索引的项目向量数量相同,并且算法已经被移植了。那么,这两个解决方案之间有什么区别呢?
对于那些查看过 C++ 代码库并可能被前面描述的内存映射问题提示的人来说,您可能已经注意到这个细微的区别:Arroy 将生成的树节点写入不同的原始文件中,而 Annoy 相反,在内存映射文件中预留空间,并直接写入。通过这种技巧,操作系统需要在内存映射区域中保留更多的空间,并被迫从缓存中失效项目节点,以使新写入的树节点在缓存中处于热状态,从而毫无理由地减慢了系统速度,因为树节点对于算法来说并不必要。
因此,经过更多的二分查找以找到 Annoy 在一台 63 GiB 的机器上的限制,我发现它大约可以索引 10M 个向量,耗时 5 小时。
无共享原则的胜利
因此,Arroy 可以在同一台机器上索引 36% 的向量,但需要多长时间呢?与单线程方式复制所有树节点相比,并行写入同一文件是否更快?由于我只进行了一些小的测试,所以这一段会很短,但 Arroy 总是更快!
| 向量数量 | 线程数量 | 构建时间 | |
|---|---|---|---|
| Annoy | 96k | 1 | 5 分 38 秒 |
| arroy | 96k | 1 | 3 分 45 秒 |
| Annoy | 96k | 12 | 1 分 9 秒 |
| arroy | 96k | 12 | 54 秒 |
| Annoy | 10M | 12 | 5 小时 40 分 |
| arroy | 10M | 12 | 4 小时 17 分 |
| Annoy | 15.625M | 12 | -- |
| arroy | 15.625M | 12 | 7 小时 22 分 |
现在,你可能告诉我,我需要大约 400GiB 的内存来索引 100M 个向量,你可能说得没错,但是 @irevoire 将在以后的文章中讨论增量索引。出于乐趣,我做了一个线性回归。根据这 12 个线程和所需的内存,我预测需要一天 22 小时 43 分钟 😬。哦!由于我们也在 Meilisearch 中使用这个向量存储,因此我们需要提供在搜索时过滤此数据结构的方法。这是本系列的下一篇文章。
你可以在 Lobste.rs、Hacker News、Rust 子reddit 或 X(前身为 Twitter) 上评论这篇文章。
本系列的第 3 部分 现已发布,探讨了我们使用 Arroy 的过滤磁盘 ANN 进行搜索的进一步改进。
Meilisearch 是一个开源搜索引擎,它不仅为最终用户提供最先进的体验,而且还提供简单直观的开发者体验。
有关 Meilisearch 的更多内容,你可以加入 Discord 上的社区或订阅 新闻稿。你可以查看 路线图 并参与 产品讨论 以了解更多关于产品的信息。