

今天,我将带您深入了解 crates.io,以及我如何使用我们的即时搜索引擎创建了一个替代搜索栏:Meilisearch。

Crates.io 是存储 Rust 社区库(软件包)的官方网站,也是 Cargo 包管理器上传、更新和下载库的地方。
Sean Griffin 是 crates.io 团队的一员,负责维护其当前的搜索引擎以及整个网站。Kornel Lesinski 建立了lib.rs,它是crates.io 的替代方案,并使用Tantivy 为其搜索栏提供支持。说实话,我更喜欢它的颜色设计,这就是我将其用作我们搜索演示的原因。
我决定运行我们的即时搜索引擎,并随着时间的推移测试其相关性,与这些现有解决方案进行比较。我们的搜索引擎使用完全不同的算法;它基于前缀搜索,并且容错。
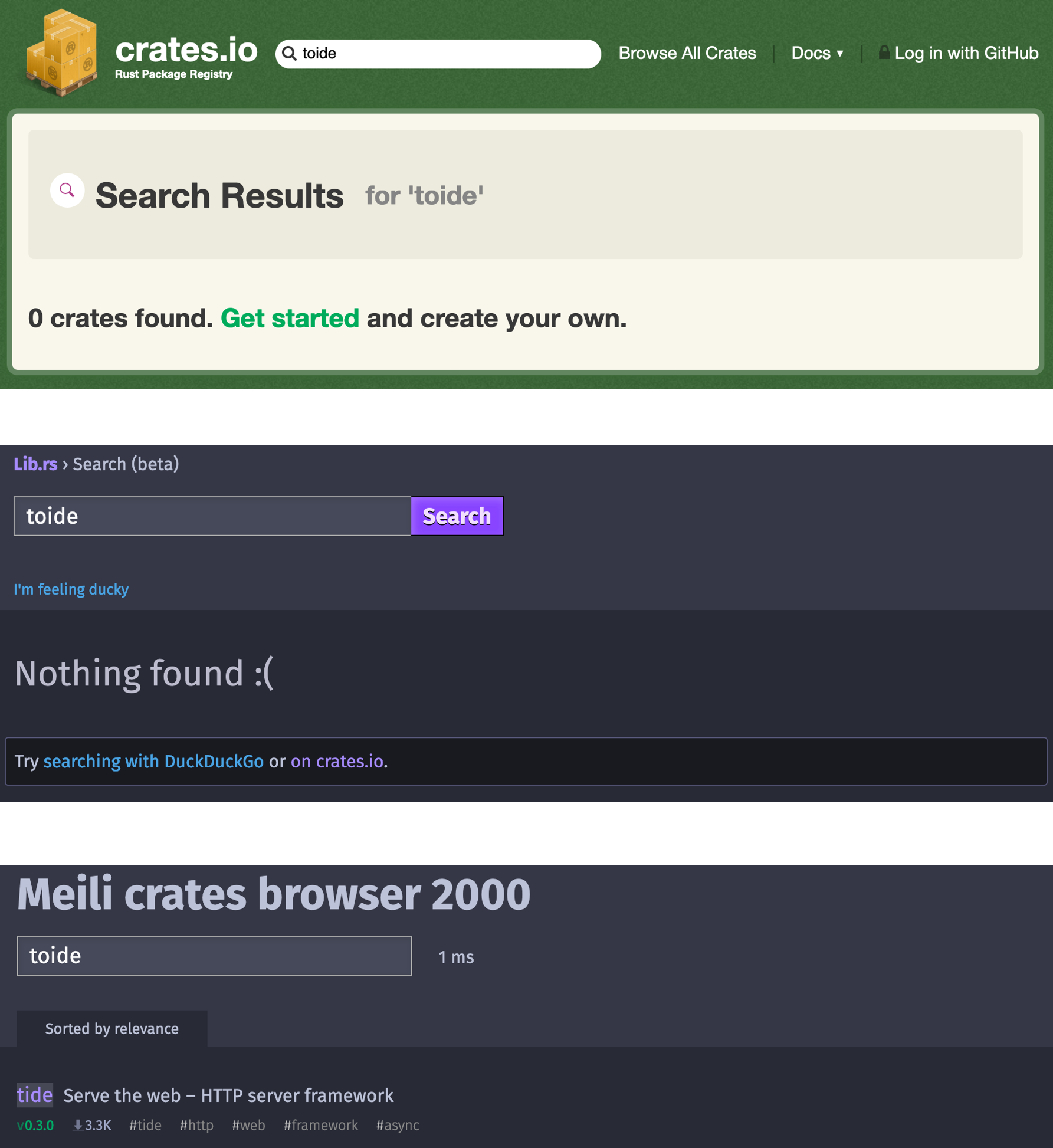
因此,我问自己:为什么不使用我们新的即时搜索引擎,并使其对心爱的社区有用呢?这将为我们提供大量反馈,并且可能在过程中获得一些 pull 请求。
在 Meili,我们管理一个内部 Kubernetes 集群,这对于为客户托管演示非常有用。此演示的 Meilisearch 服务器目前在该集群中的一个 Pod 上运行。
为了让 Meilisearch 展示这些库,我们需要找到 crates.io 上所有当前可用的软件包。幸运的是,此索引在 GitHub 上以几个子文件夹的形式提供,这些子文件夹包含软件包的名称和版本,其中包含类似于 *32 000* 个文件的内容。每当库更新到新版本或版本被撤回时,都会进行一次提交。
因此,我使用了crates.io-index 仓库 来 **初始化** 我们新创建的 Meili 搜索引擎,但首先需要更多数据,例如,每个库的描述、关键词和类别。同样,Rust crates.io 团队帮助了我们,我和Pietro Albini 进行了交谈,他向我指出了未限速的服务器,这些服务器提供软件包内容。
现在我们可以检索有用的数据,我创建了一个异步爬虫,它下载、提取、检索 Cargo.toml,并将基本数据上传到 Meilisearch。

Meilisearch 现在理解这些数据,并为我们提供即时、相关且容错的响应。但是,新的库怎么办?我们希望收到有关新库的通知,并能够将它们发送到 Meilisearch。
Docs.rs 是计算和存储 crates.io 托管的所有 Rust 软件包文档的官方网站。它每分钟都会对 crates.io 索引进行差异比较,以了解有关新库更新的信息。幸运的是,它提供了这些更新的 Atom 提要。
这就是Heroku 登场的地方。Heroku 在他们的服务器上提供类似于 *1000* 小时免费计算能力,并为我们提供调度程序。我们可以使用这些积分,并免费询问 docs.rs 有关新更新的库,每 10 分钟一次,通过获取 Atom 提要,像以前一样下载更新的软件包,最后更新我们的搜索引擎,**实时**!
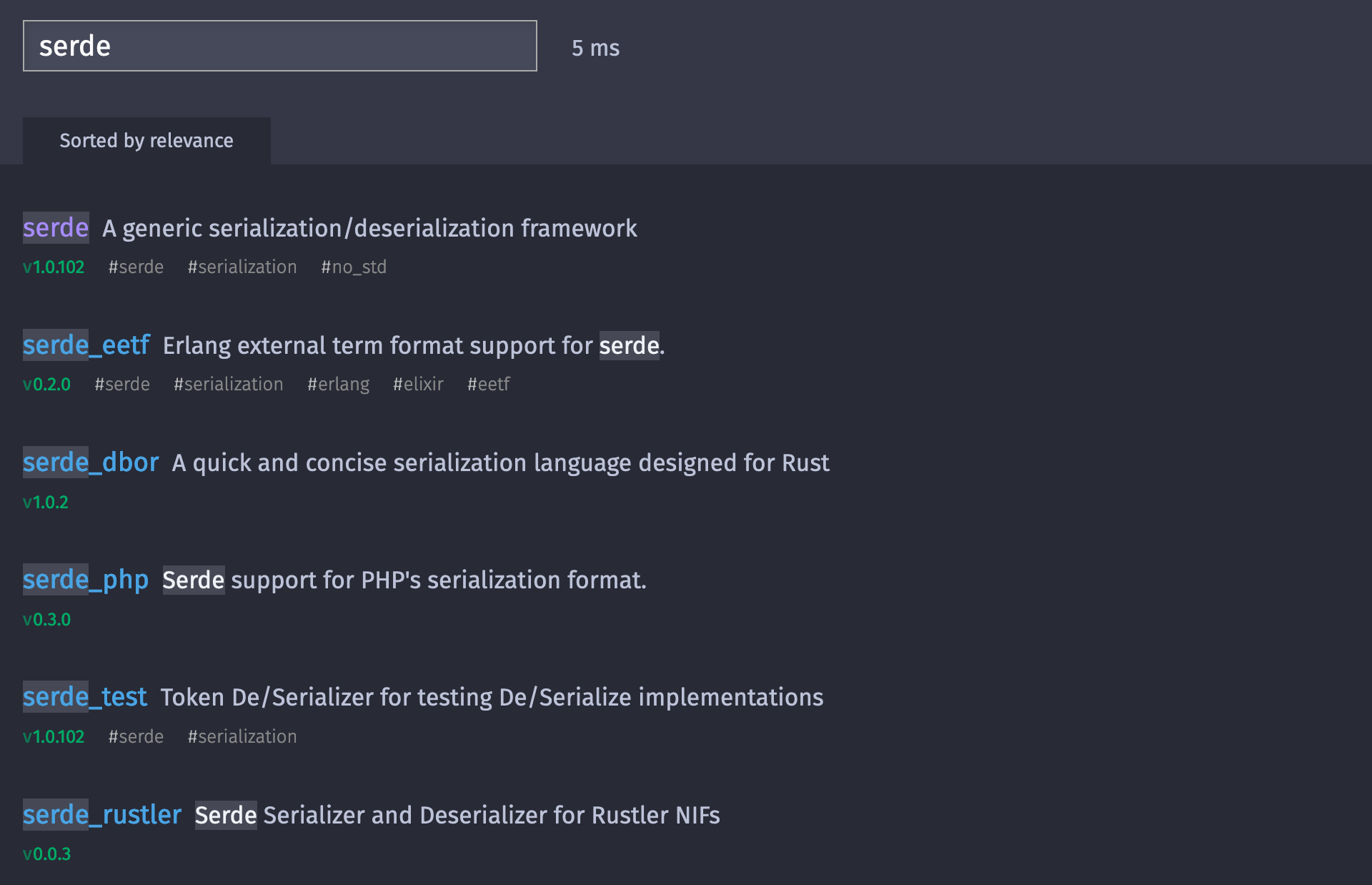
搜索结果令人满意,但并非预期的那样,有些地方不对。例如,当我们输入“serde”时,第一个结果是相关的,但后面的结果就不相关了。这与 Meilisearch 除了查询匹配词之外,没有足够的数据来对库进行评级有关。
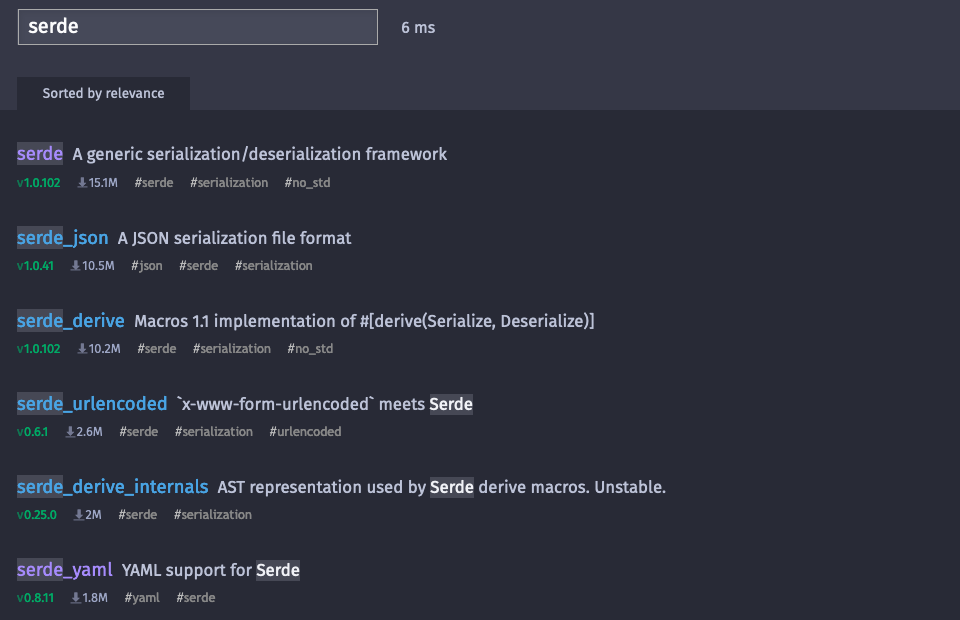
**下载次数** 惊人地改善了搜索结果。此数据可通过 crates.io 获取。每天都会进行一次完整数据库导出,其中包含每个库的下载次数。我决定将这些作为最后的排名标准,以帮助 Meilisearch 解决被视为相等的库。
我部署了一个 Heroku 调度程序,每天运行一次以更新所有库的下载次数;下载 tarball、提取它、读取 CSV 并将 *32 000* 个库下载次数上传到 Meilisearch 需要大约 30 秒。所以我们离每月 *1000* 小时免费使用还很远。
我认为这个搜索演示相当不错,但我还在考虑添加同义词和停用词,因为 Meilisearch 支持这些功能。例如,输入“db”并看到与“database”相关的结果会很方便。停用词将有助于忽略无用的词语,例如“the”或“that”,这些词语有时会污染搜索结果,但我们需要小心,因为库名称可能由停用词组成。
Meilisearch 还支持基本过滤,将来能够在某个类别或具有特定关键词的库中搜索将非常棒。
所有这些改进都可以由您完成;演示是开源的。核心引擎源代码 也在 GitHub 上提供,这就是这篇文章的全部意义!请查看并讨论它,参与的人越多,功能越多!