

这是博客文章系列的第一部分,最初发表在我的个人博客上。
整合关键字搜索和语义搜索
在 Meilisearch 我们正在努力进行混合搜索,将广泛使用的关键字搜索算法与不太常见的语义搜索相结合。前者非常擅长精确匹配,而后者可以找到你可以 描述 得更好的内容。
我将解释为什么我们甚至要谈论 Meilisearch/arroy 以及它对我们为什么如此重要。语义搜索对我们来说是全新的事物。原理很简单:文档与向量(浮点数列表)相关联,它们彼此越接近,语义上就越接近。当用户查询引擎时,您计算查询的嵌入(向量),并进行近似最近邻搜索,以获取与用户查询最接近的第 n 个项目。有趣的事实:经过这么长时间,Annoy 仍然是顶级竞争者之一,所以想象一下当我们最终发布 Arroy 时会发生什么。
看起来很简单,对吧?你 真的 认为这系列博客文章会讨论一个非常简单的主题吗?加入我们,与 @irevoire 和我(@Kerollmops)一起踏上旅程,在 @dureuill 的协助下,将这个尖端的库移植到 Rust 中。
优化高维嵌入的存储和搜索
嵌入的维度在 768 到 1536 之间。Meilisearch 的客户希望存储超过 1 亿个嵌入。没有经过任何降维算法修改的嵌入使用 32 位浮点数。这意味着存储这些数据将需要 286 GiB 到 572 GiB 之间,具体取决于维度。
是的,它适合内存,但代价是什么?存储在磁盘上要便宜得多。Ho!而且这仅仅是原始向量。我向你保证,在所有向量中进行近似邻搜索 O(n) 将非常慢。因此我们决定将它们存储在磁盘上。在选择 Spotify/Annoy 之前,我们研究了许多不同的解决方案。最初,我们使用 instant-distance Rust crate 中的 HNSW,另一种数据结构,来执行 ANNs(近似最近邻)搜索。但是,它不是基于磁盘的;所有内容都存在于内存中,这是不切实际的。
Spotify 的超平面树,用于高效的 ANNs
Spotify 开发了一个很棒的 C++ 库,用于在巨大的向量集中进行搜索。该算法会生成多个引用向量的树。树节点是随机的超平面,将向量子集一分为二。根节点将整个向量集一分为二,左右分支递归地再次将向量子集一分为二,直到子集足够小。当我们执行 ANNs 搜索时,我们会遍历所有根树,并根据提供的搜索集决定是沿着超平面的左侧还是右侧前进。好处是每个节点和向量都直接存储在内存映射文件中。
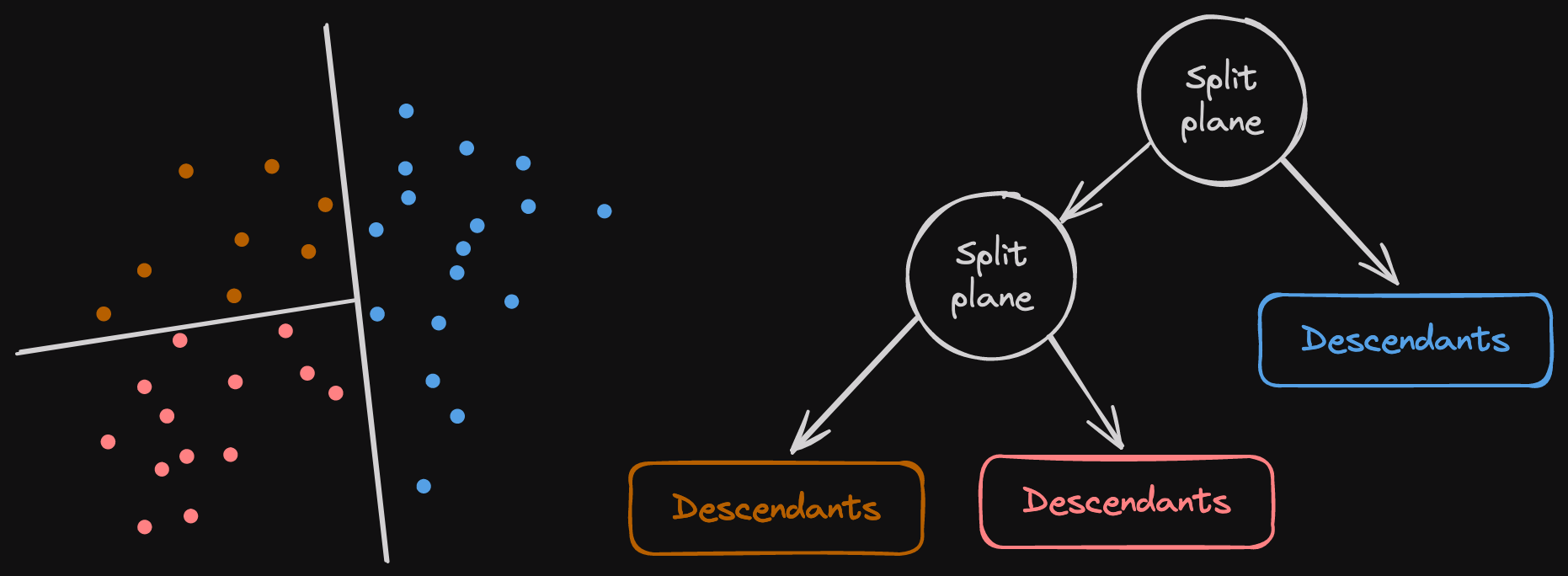
在树的末尾,我们可以看到后代节点。这些定义了最终的叶向量列表,它们适合在上述递归分割节点的这一侧。它是一个由用户提供的无符号整数列表。Annoy 将它们表示为 u32 的切片,但我们决定使用 RoaringBitmaps 来减小它们的大小。Annoy 无法压缩它们,因为它们有一个有趣的限制:所有节点、用户叶向量、分割节点和后代必须具有相同的大小,以便使用磁盘上的偏移量进行访问。
上面的图像显示了分割平面的表示方式。一个超平面将这里的一组节点分割成两个维度,但想象一下,它拥有 768 到 1536 个维度。每个超平面都会递归地创建两个点子集,这些子集被另一个超平面分割。一旦要分割的点数足够少,我们就创建一个包含与这些点对应的项 ID 的后代节点。此外,点的嵌入从未在内存中重复;我们通过它们的 ID 来引用它们。
将 Annoy 适配到 LMDB
那么,如果它运行良好,为什么我们必须将其移植到 Rust 呢?第一,因为我遵循 用 Rust 重写 的教条😛,第二,因为这是一个 C++ 库,其中有很多可怕的黑客和未定义的行为,第三,因为 Meilisearch 基于 LMDB,一个原子、基于事务的、内存映射的键值存储。此外, 自 2015 年以来,他们一直想使用 LMDB,但他们还没有实现它;这需要很多时间来相应地更改数据结构。
LMDB 使用 BTree 对条目进行排序,它比 annoy 占用更多的中间数据结构空间,annoy 通过文件中的偏移量直接识别向量。使用这个键值存储的另一个优势是管理增量更新。插入和删除向量变得更容易。假设您在 Annoy 中插入一个由高 32 位整数标识的向量。在这种情况下,它将分配大量内存来存储它作为专用偏移量,如果必要,还会增加文件大小。
在 Meilisearch 和 Arroy 中, 我们使用 heed,一个类型化的 LMDB Rust 包装器,以避免与 C/C++ 库相关的未定义行为、错误和问题。因此,我们广泛使用 &mut 和 & ,以确保我们在保留键值存储条目中的引用时不会修改它们,并确保读写事务不能在不同线程之间被引用或发送。但这将是另一个故事。
我们最初认为使用这个键值存储会使 Arroy 比 Annoy 慢。但是,LMDB 在将页面写入磁盘之前会在内存中写入它们,这似乎比直接写入可变内存映射区域快得多。另一方面,LMDB 不保证 Annoy 文件格式允许的值的内存对齐;我们稍后会讨论这个问题。
使用 SIMD 优化向量处理
Arroy 应该执行的最 CPU 密集型任务是尝试将向量云一分为二。这需要在热循环中计算大量的距离。但我们从内存映射磁盘读取嵌入。可能会出现什么问题?
fn align_floats(unaligned_bytes: &[u8]) -> Vec<f32> {
let count = unaligned_bytes.len() / mem::size_of::<f32>();
let mut floats = vec![f32::NAN; count];
cast_slice_mut(&mut floats).copy_from_slice(unaligned_bytes);
floats
}我们在 macOS 上使用 Instrument 对我们的程序进行分析,发现很多时间都花在四处移动东西上,即 _platform_memmove。原因是从磁盘读取未对齐的浮点数是未定义的行为,因此我们将浮点数复制到一个对齐的内存区域,如上所示。成本:读取一次分配,再加上调用 memmove。
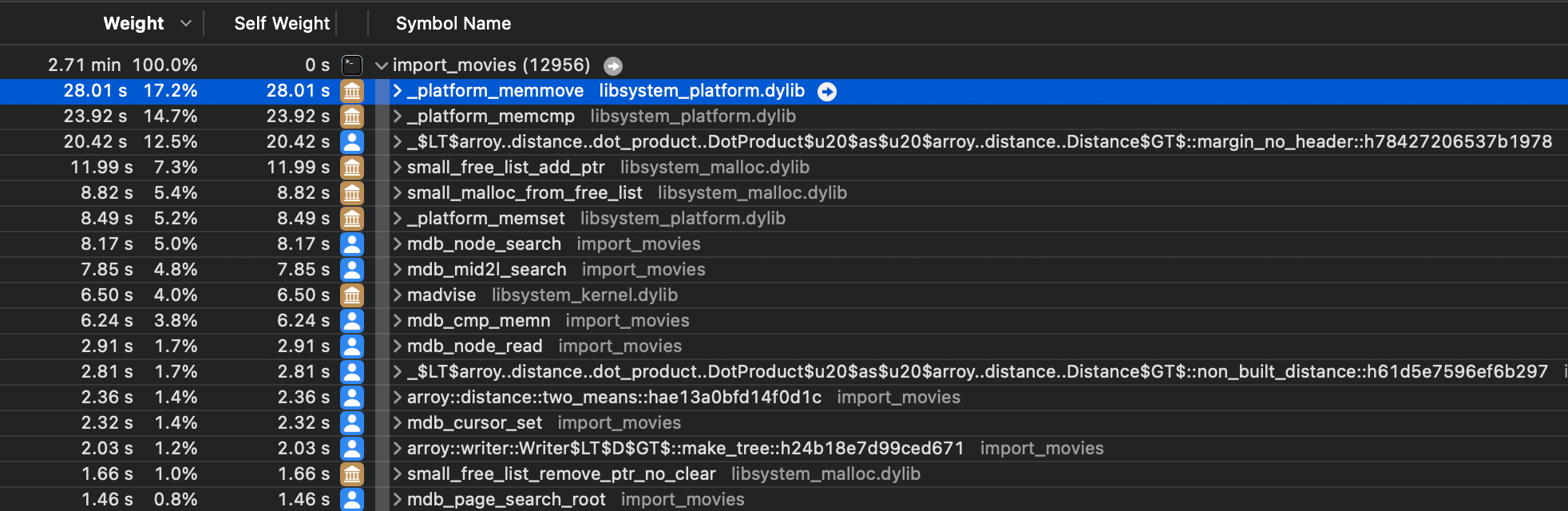
在将距离函数从 C++ 移植到 Rust 时,我们使用了 Qdrant SIMD 优化的距离函数,事先没有修改它们。尽管, 意识到读取未对齐内存的性能成本,我们决定在未对齐的浮点数上执行距离函数,确保不要将其表示为 &[f32] ,因为这将是未定义的行为。这些函数接受字节的原始切片,并使用指针和 SIMD 函数处理它们。我们解锁了性能。距离函数更慢,但它弥补了 memmove 和分配的不足!
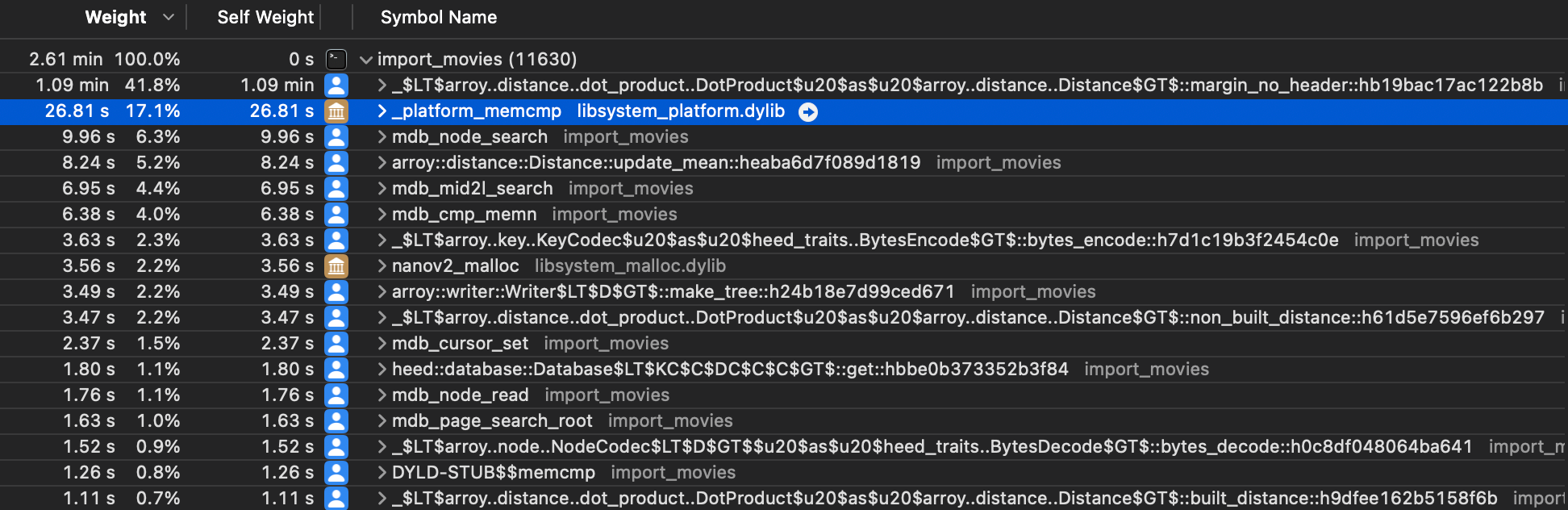
与 memmove 调用类似,我们可以看到 _platform_memcmp 函数在这里占用大量空间。原因是 LMDB 使用此标准函数来比较键字节并决定键在树中的词典顺序上是位于另一个键之上还是之下。每当我们在 LMDB 中读取或写入时,都会使用它。 @irevoire 大幅减少了键的大小,并看到了重要的性能提升。我们进一步尝试使用 MDB_INTEGERKEY,它使 LMDB 使用计算机字节序来比较内存,但这使用起来很复杂,并且没有显示出显著的性能提升。
即将到来的挑战
在将这个很酷的算法移植到 Rust 和 LMDB 时,我们缺少一个最重要的功能:多线程树构建。造成这种缺少功能的主要原因是 LMDB,它不支持对磁盘的并发写入。这是这个库的魅力所在;写入是确定的。我们已经非常了解 LMDB,我们将在本系列的第 2 部分解释我们如何利用 LMDB 的强大功能,以及我们如何超越 Spotify 库。
除了使当前的 Annoy 功能均衡之外,我们还需要更多功能来满足 Meilisearch 的需求。我们在 Arroy 中实现了 微软的 Filtered-DiskANN 功能。通过提供我们想要检索的项 ID 子集,我们可以避免搜索整个树来获取近似最近邻。我们将在即将发布的文章中讨论这一点。
在 Meilisearch v1.6 中,我们优化了仅更新文档部分的性能,例如投票计数或查看次数。上面描述的 Arroy 单线程版本为每个向量调整重新构建树节点。 @irevoire 将在下一篇文章中探讨 Arroy 的增量索引,这是 Annoy 不具备的功能。
您可以在 Lobste.rs、 Hacker News、 Rust 子版块 或 X(前身为 Twitter) 上评论这篇文章。
第二部分 和 第三部分 现在已发布,探讨了 Rust 中 ANN 算法的进一步发展。
Meilisearch 是一个开源搜索引擎,它不仅为最终用户提供最先进的体验,而且还提供简单直观的开发人员体验。
有关 Meilisearch 的更多内容,您可以加入 Discord 上的社区或订阅 新闻稿。您可以通过查看 路线图 并参与 产品讨论,详细了解该产品。