

Oyez, oyez!Meilisearch 的新版本已经发布,它带来了很多酷炫的新功能,包括一个大家期待已久的功能:拼写容错自定义!
我们一直收到用户关于希望禁用或微调拼写容错的反馈。Meilisearch v0.21 引入了短语搜索,它在双引号中包含查询词的情况下,会返回包含这些查询词的精确文档,例如:“african-american poet”。
这是迈向满足用户需求的一大步,但还不够。在仔细研究了这个问题之后,时机已到:拼写容错的自定义已成为现实🎉
但是等等,自定义拼写容错到底意味着什么?更重要的是,拼写容错是什么意思?
良好的旧默认行为
Meilisearch 具有拼写容错功能,这意味着它即使存在拼写错误也能理解您的搜索。但权力越大,责任越大,这意味着要设置界限以保持结果的相关性。这转化为以下三个规则
- 如果查询词少于 5 个字符,则不允许拼写错误
- 如果查询词介于 5 到 8 个字符之间,则只允许 1 个拼写错误
- 如果查询词超过 8 个字符,则允许 2 个拼写错误
因此,如果您要查找 lost,但不小心输入了 last,您将无法获得所需的结果,因为它只有 4 个字符。
但是,输入 greeec代替 greece 会检索到预期的文档,因为它有 6 个字符,所以允许一个拼写错误。
这些规则默认应用,是 Meilisearch 开箱即用配置的一部分,提供强大且相关的搜索。然而,正如他们所说,规则是为了打破而存在的...
自定义:新的可能性视野
我们知道每个项目都不同,有些用户需要配置拼写容错以适应其项目的特殊性。我们听到了您的声音!
让我们看看新的拼写容错设置
"typoTolerance": {
"enabled": true,
"minWordSizeForTypos": {
"oneTypo": 5,
"twoTypos": 10
},
"disableOnWords": [],
"disableOnAttributes": []
}
查看上面的 typoTolerance 对象,您现在可以
- 通过设置
"enabled": false😱 完全禁用拼写容错 - 使用
"disableOnWords"部分禁用一组特定词语上的拼写容错 - 禁用所需文档属性上的拼写容错
"disableOnAttributes"
您还可以通过修改允许一个或两个拼写错误的单词的最小大小来微调拼写容错设置。
总之,您可以完全控制该功能。
试试看
俗话说,一张图片胜过千言万语(我忍不住要使用这些口头禅,抱歉);因此,我创建了一个演示,以显示不同的拼写容错配置如何影响返回的搜索结果。您可以在这里测试它。
我们将使用Hakan Özler 的书籍数据集。为了演示目的,我对原始数据集做了一些更改,您可以在 GitHub 上找到转换后的数据集。您可以通过书名、ISBN(书籍的 ID)、作者或书籍描述中的词语来搜索书籍。
我创建了两个具有不同拼写容错设置的相同索引。一个索引使用开箱即用的拼写容错设置,而另一个索引使用以下设置
const customTypoTolerance = {
disableOnAttributes: ['isbn'],
minWordSizeForTypos: {
oneTypo: 2,
twoTypos: 4
}
}isbn 上禁用拼写容错,并且允许在较短的单词上出现拼写错误:对于长度为 2 和 3 个字符的单词,允许一个拼写错误;对于任何更长的单词,允许两个拼写错误。
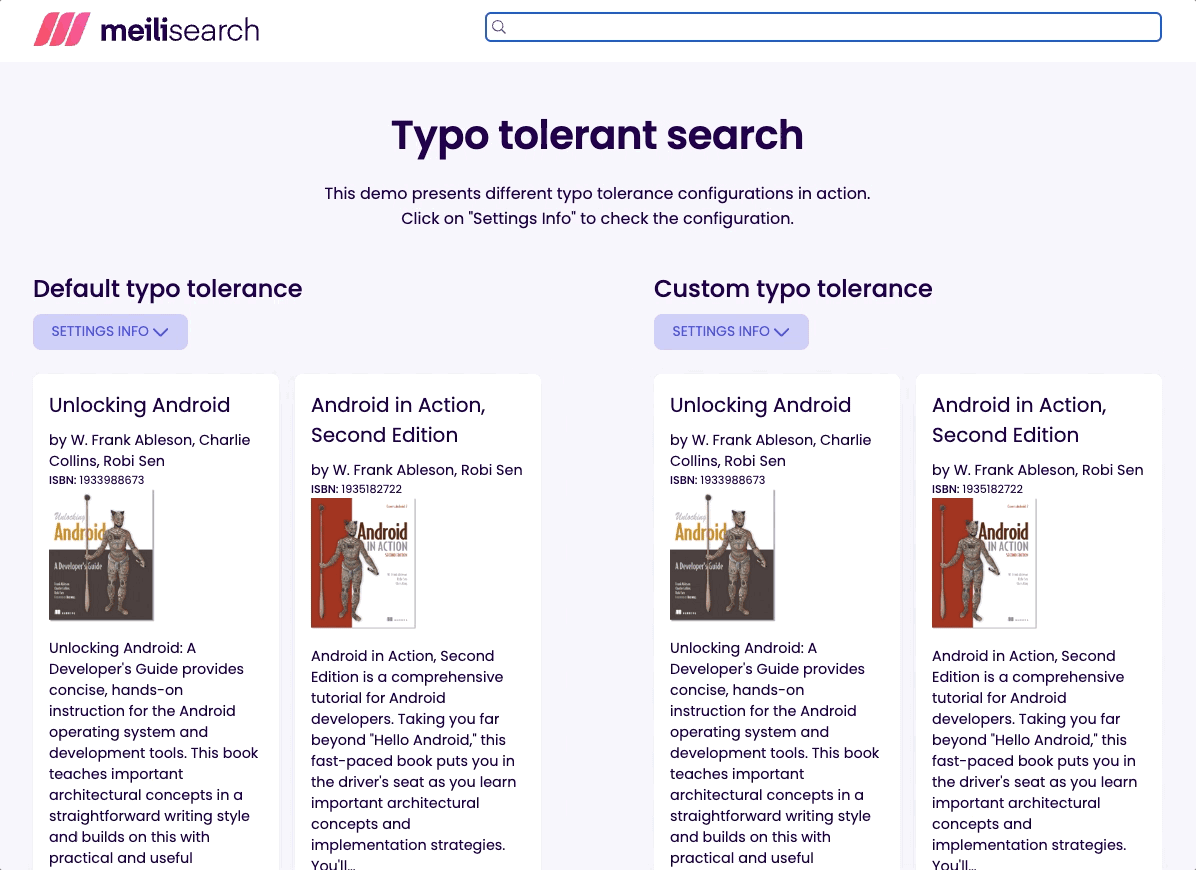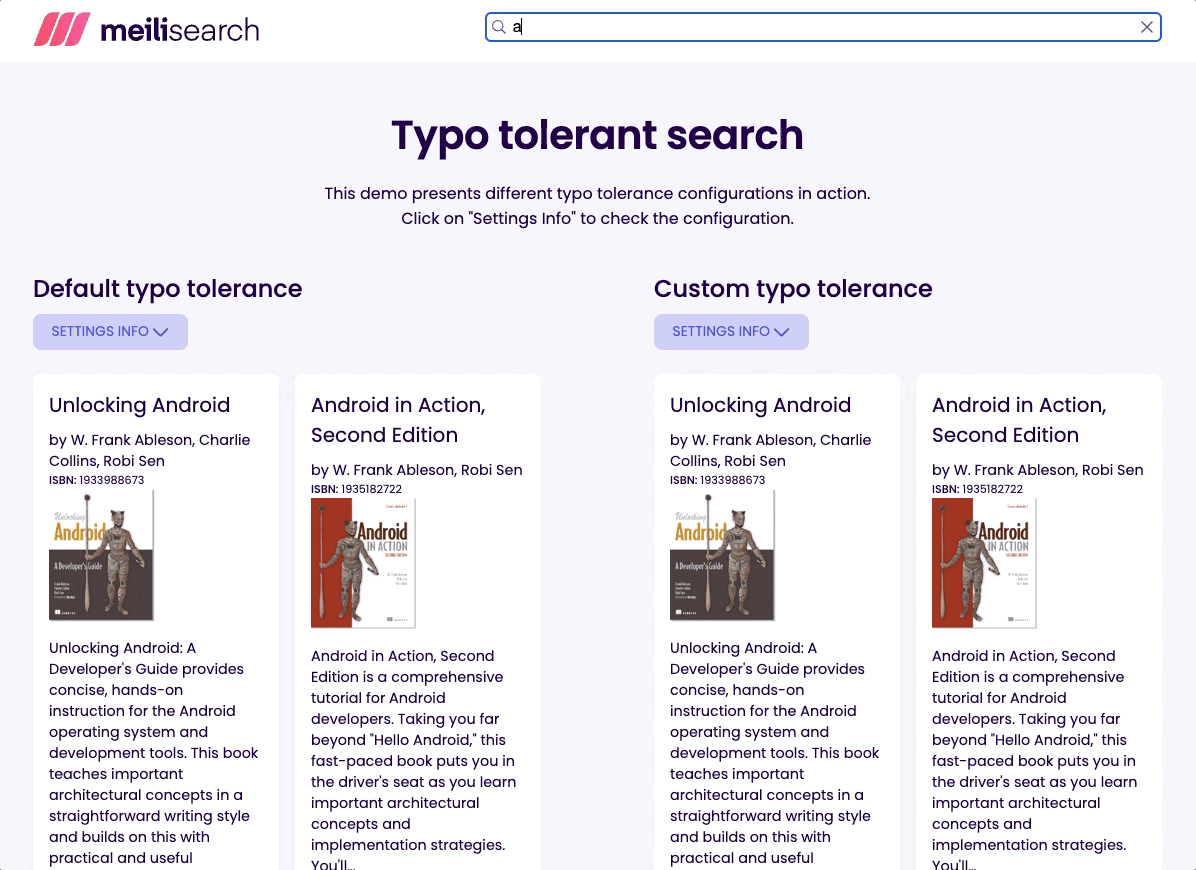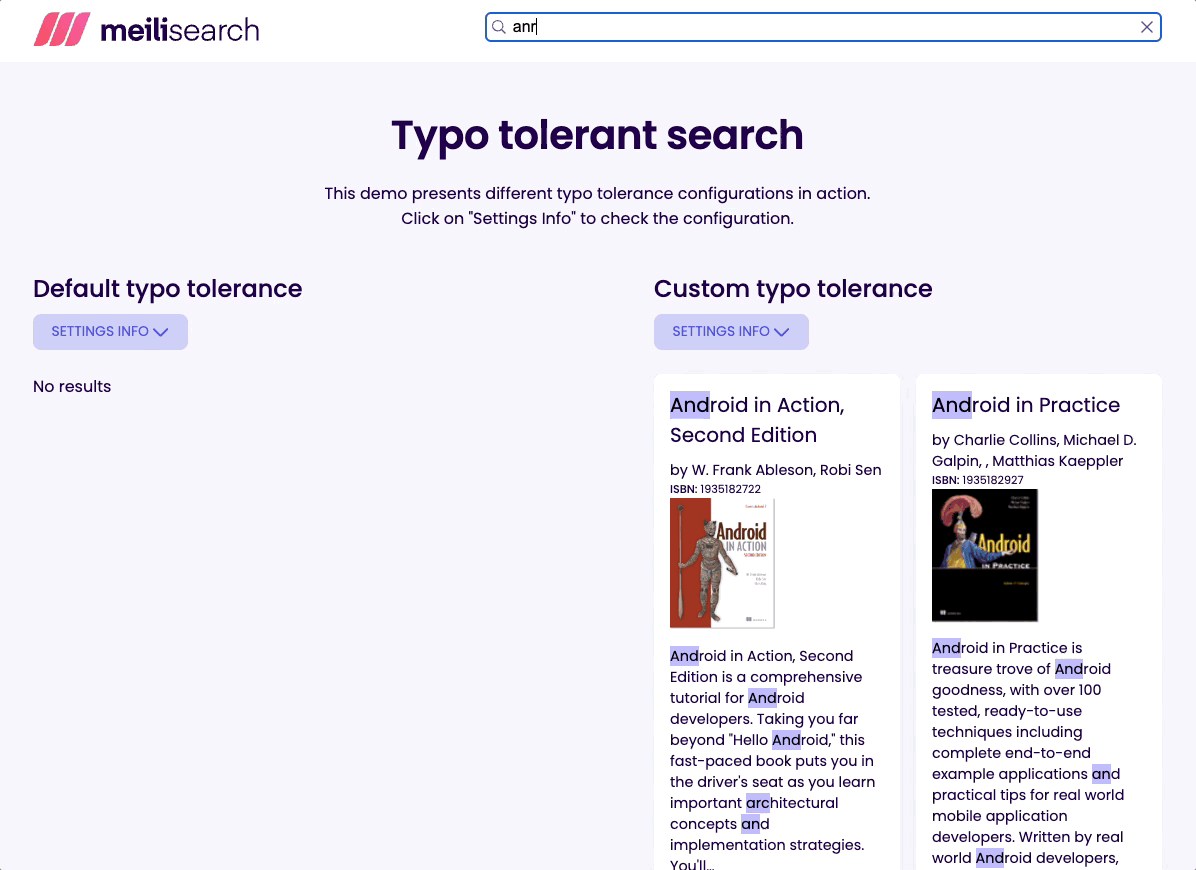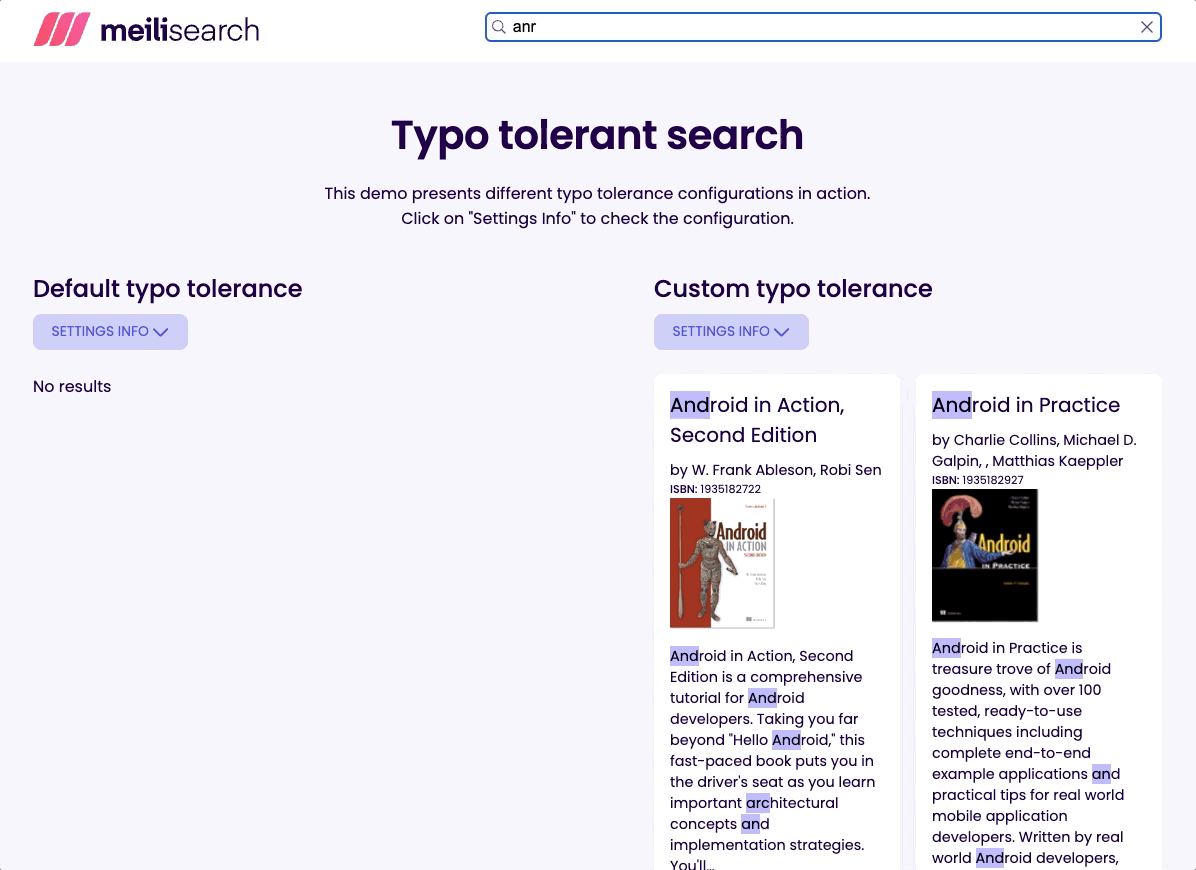
通常最好为最终用户提供一些结果,而不是没有任何结果。这就是为什么我将阈值设置为最低推荐值。试试输入 flx 并看看会发生什么!
但是,有时最好只返回精确匹配项。例如,在通过其唯一标识符搜索文档时。ISBN 就是这样:一本书的 ID。因此,我在 isbn 属性上禁用了拼写容错。
让我们尝试通过其 ISBN 查找名为 “Well-Grounded Rubyist” 的书;在搜索栏中输入 1933988657。
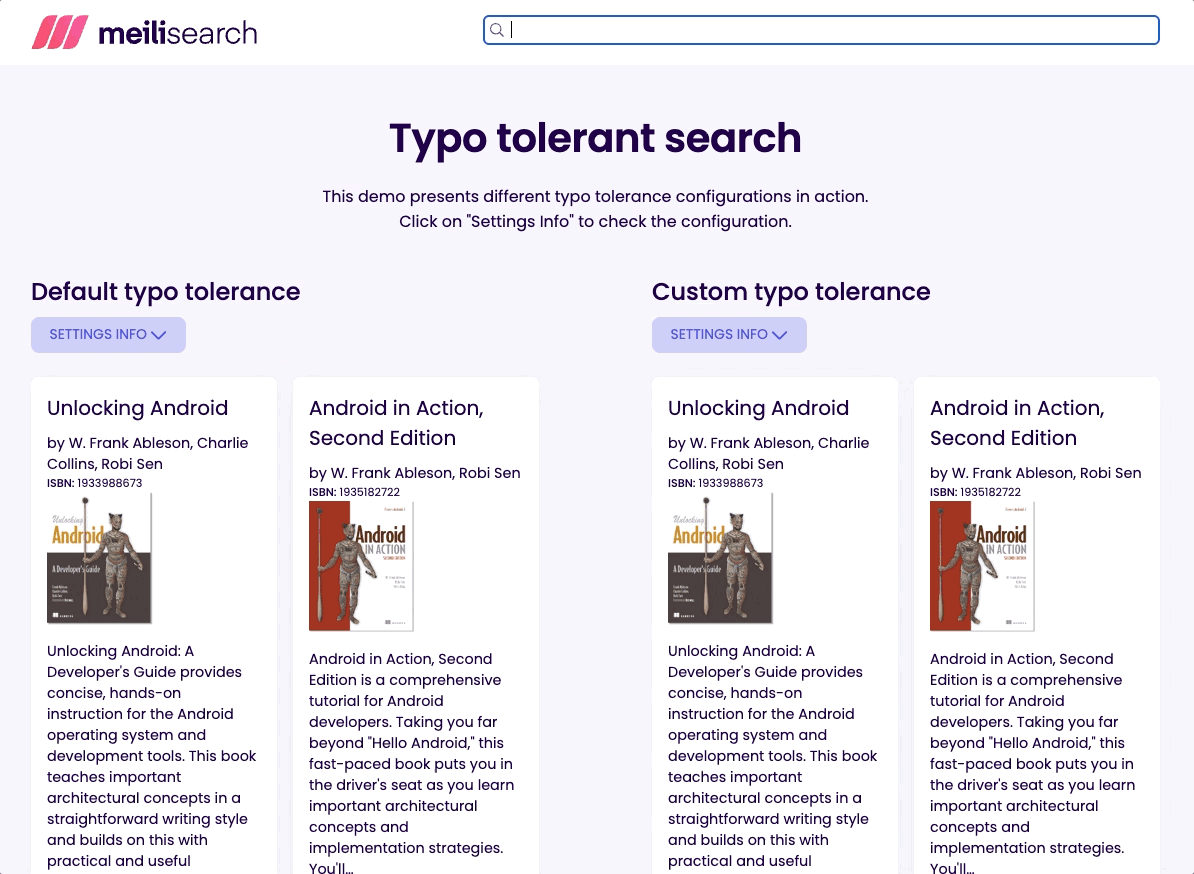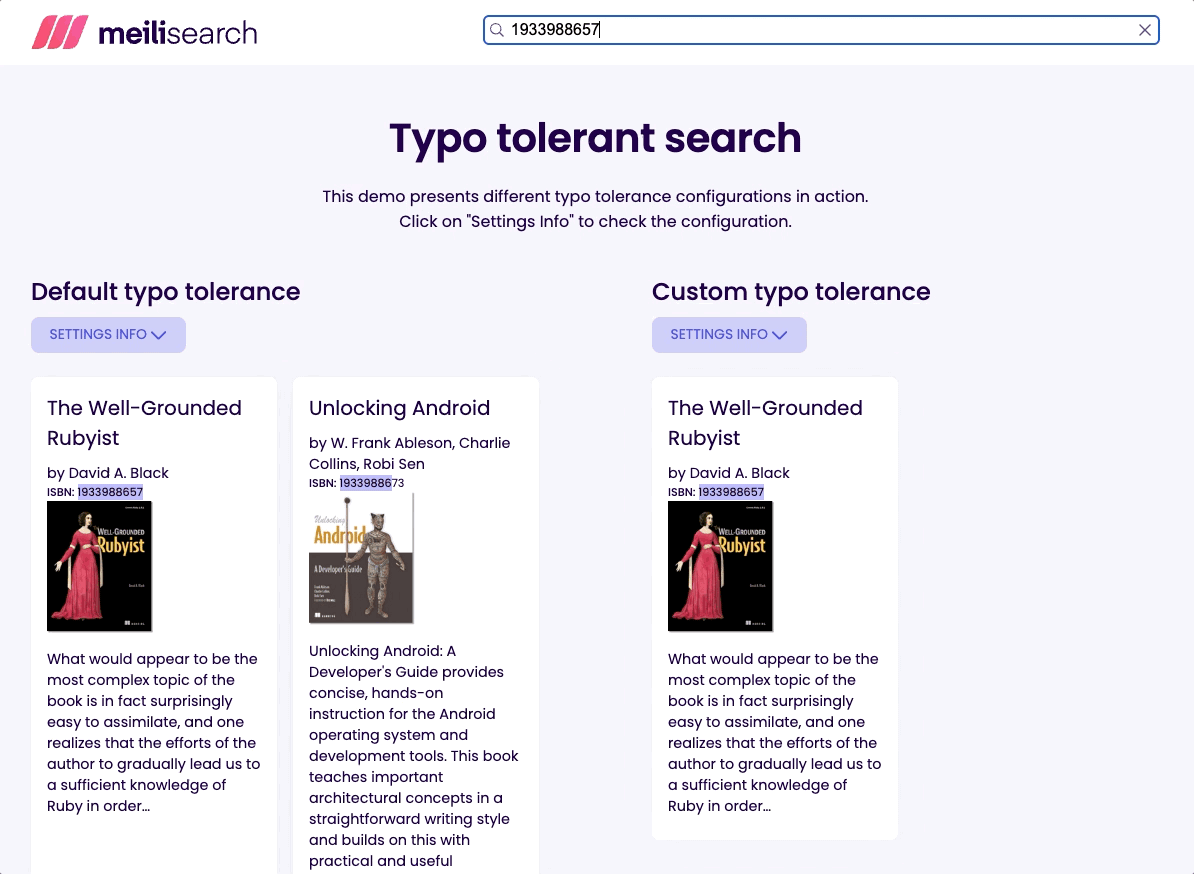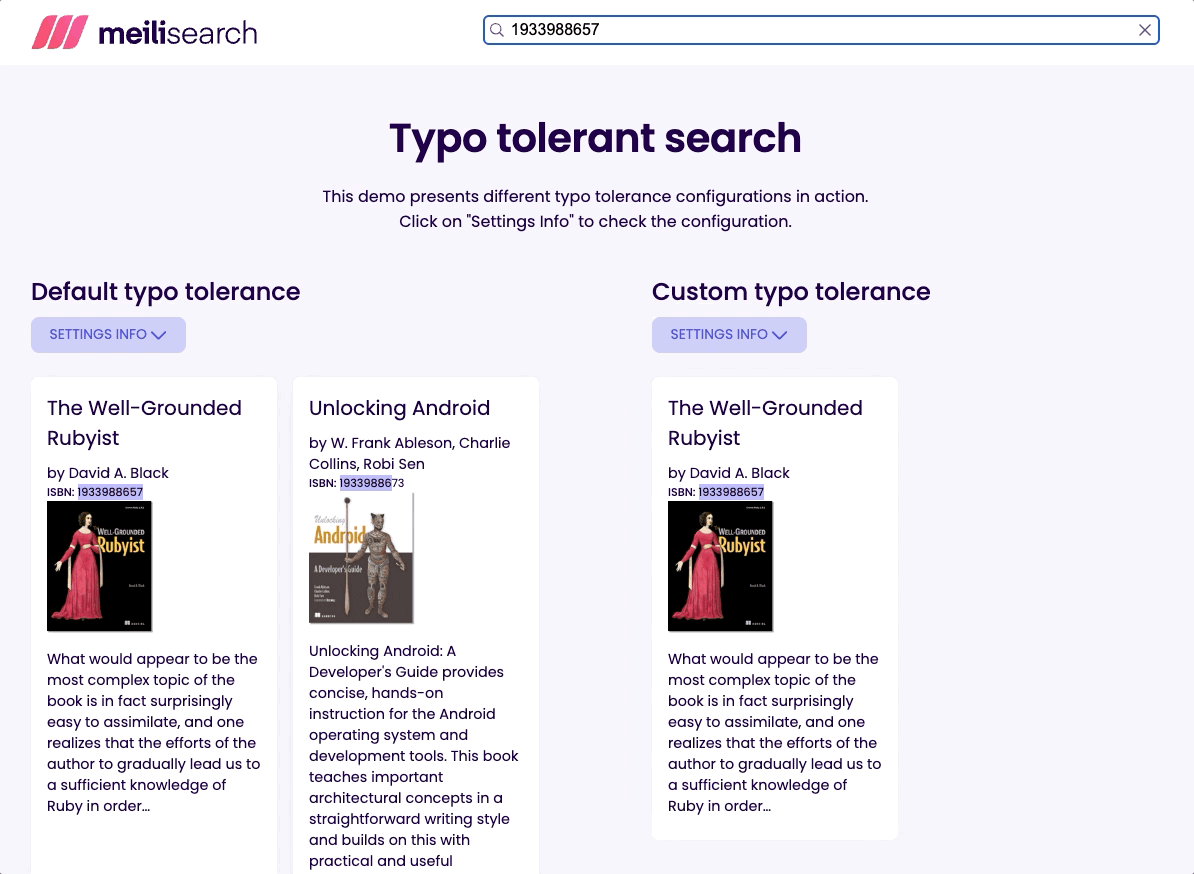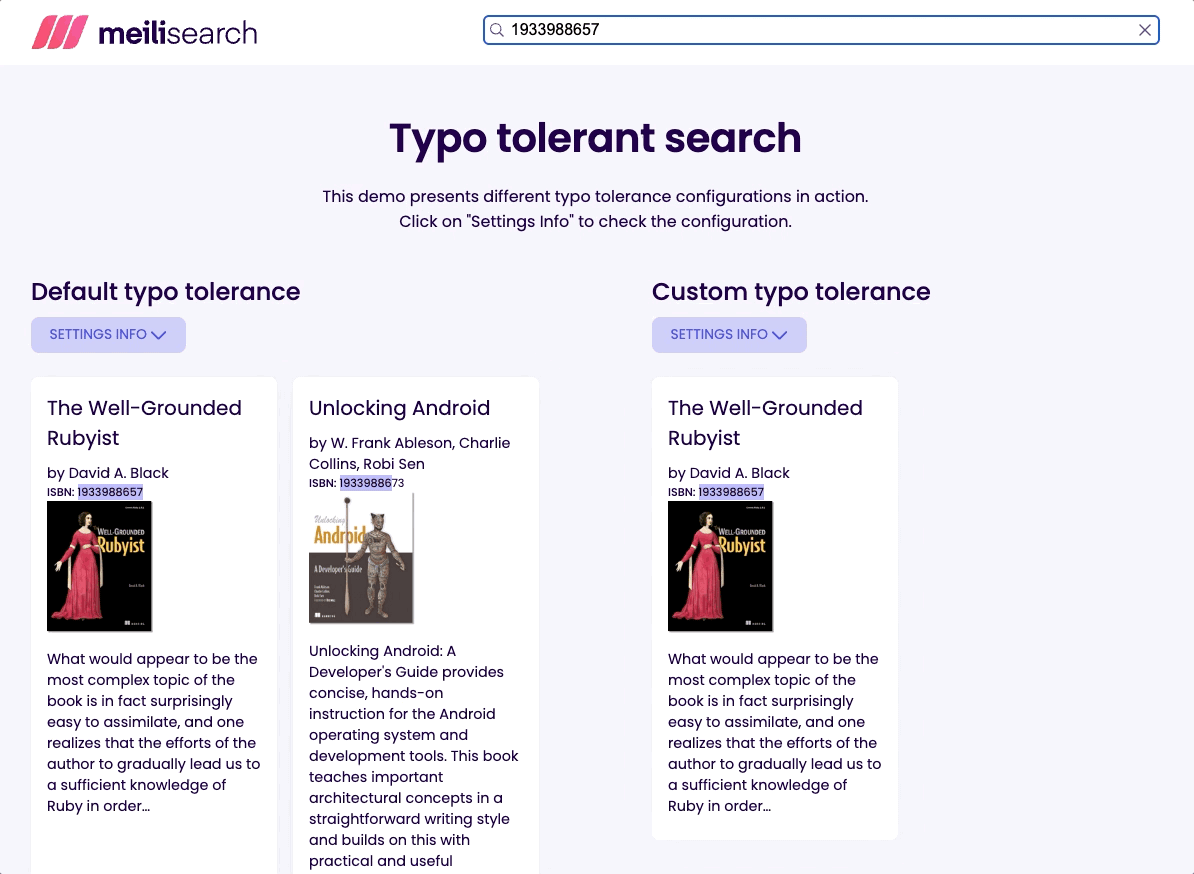
如您所见,我们使用两种设置都获得了所需的书籍。但是,当启用拼写容错时,我们得到了不止一个结果。搜索无效 ISBN,例如 1933988676,当启用拼写容错时仍然会返回结果;这可能会令人困惑和误导。
结论
我没有在任何词语上禁用拼写容错,因为我认为鉴于此数据集没有必要,您呢?如果您想做一些修改并尝试获得更相关的结果,请随意:您可以在GitHub 上找到代码。
但是,如果您喜欢真正的挑战,我有一个挑战要给您。Literal 是一个面向书籍阅读者的在线平台,它使用 Meilisearch 来搜索书架。他们非常乐意分享他们一直用来提供相关搜索结果的秘诀
{
"displayedAttributes":[
"id",
"title",
"workId",
"authors",
"categories",
"popularity"
],
"searchableAttributes":[
"authors",
"title",
"categories"
],
"filterableAttributes":[
"isbn10",
"isbn13",
"language"
],
"distinctAttribute":"workId",
"rankingRules":[
"words",
"typo",
"popularity:desc",
"proximity",
"attribute",
"sort",
"exactness"
]
}
您能想出一个更好的配置吗?您能想到完美的拼写容错设置来提高相关性吗?
您可能已经注意到,我们非常重视用户反馈。请随时查看我们的公开路线图,为您希望在未来版本中看到的任何功能投票,或提交新的功能想法。您也可以查看我们的产品仓库,提出建议或加入有关改进产品的现有讨论。
如果您喜欢 Meilisearch 并想支持我们,在GitHub 上给个星标就意味着很多 🥰